Course Overview
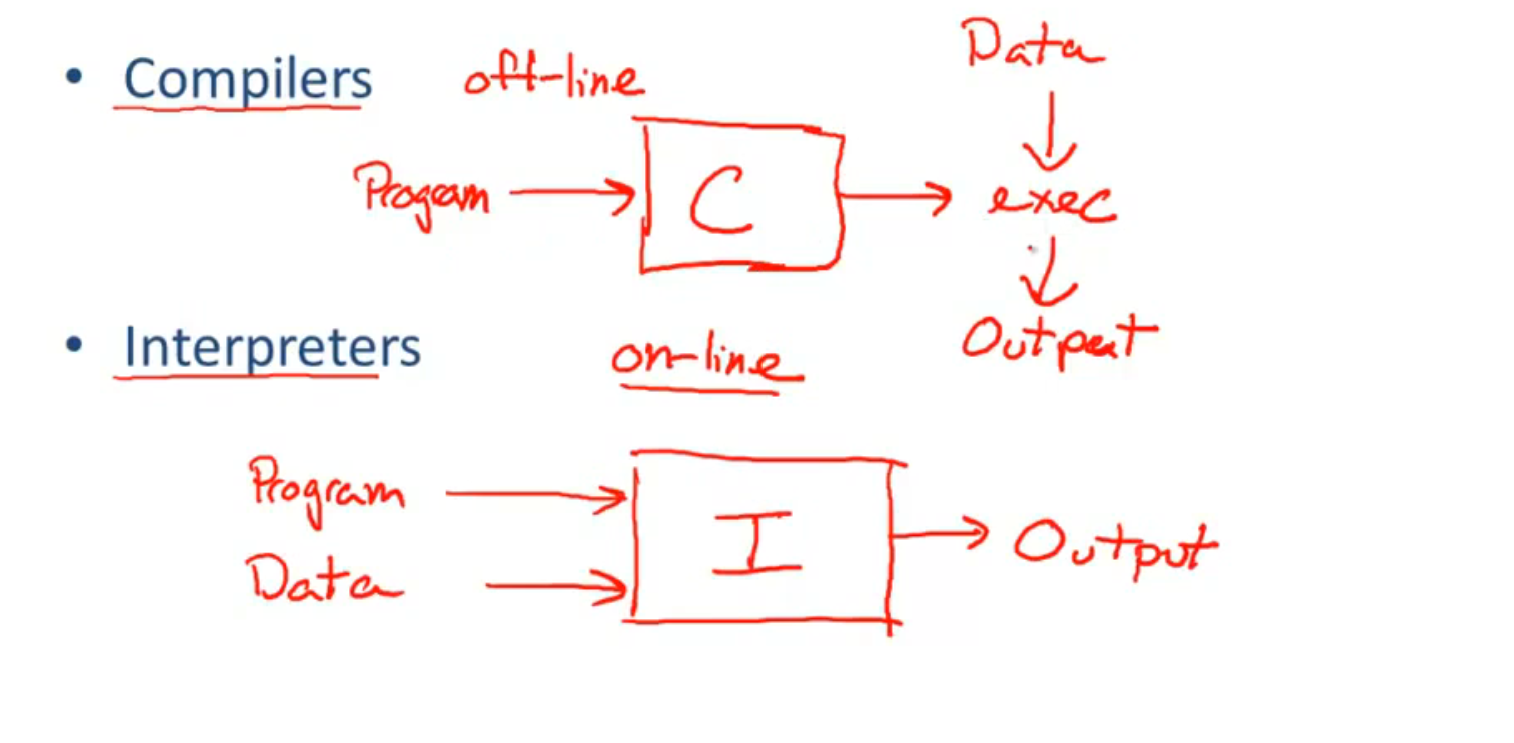
Interpreters: on-line (速度慢, 占用内存大)
Compilers: off-line
Compiler Five Phases:
-
Lexical Analysis: syntactic
recognize words

-
Parsing: syntactic: syntactic
diagramming sentences
-
Semantic Analysis: types and scopes
understand meaning (hard), catch inconsistencies
无法做到真正的解析语义, 所以只是寻找程序中自相矛盾的地方, 比如: 变量重复定义, 变量前后类型不同
-
Optimization
run faster, use less memory, less power, network, database…
-
Code Generation: translation to another languages, machine code or even high level programming language
编译器的提升:

The Course Project
COOL: Classroom Object Oriented Language
COOL 的语法
-
main 的返回值

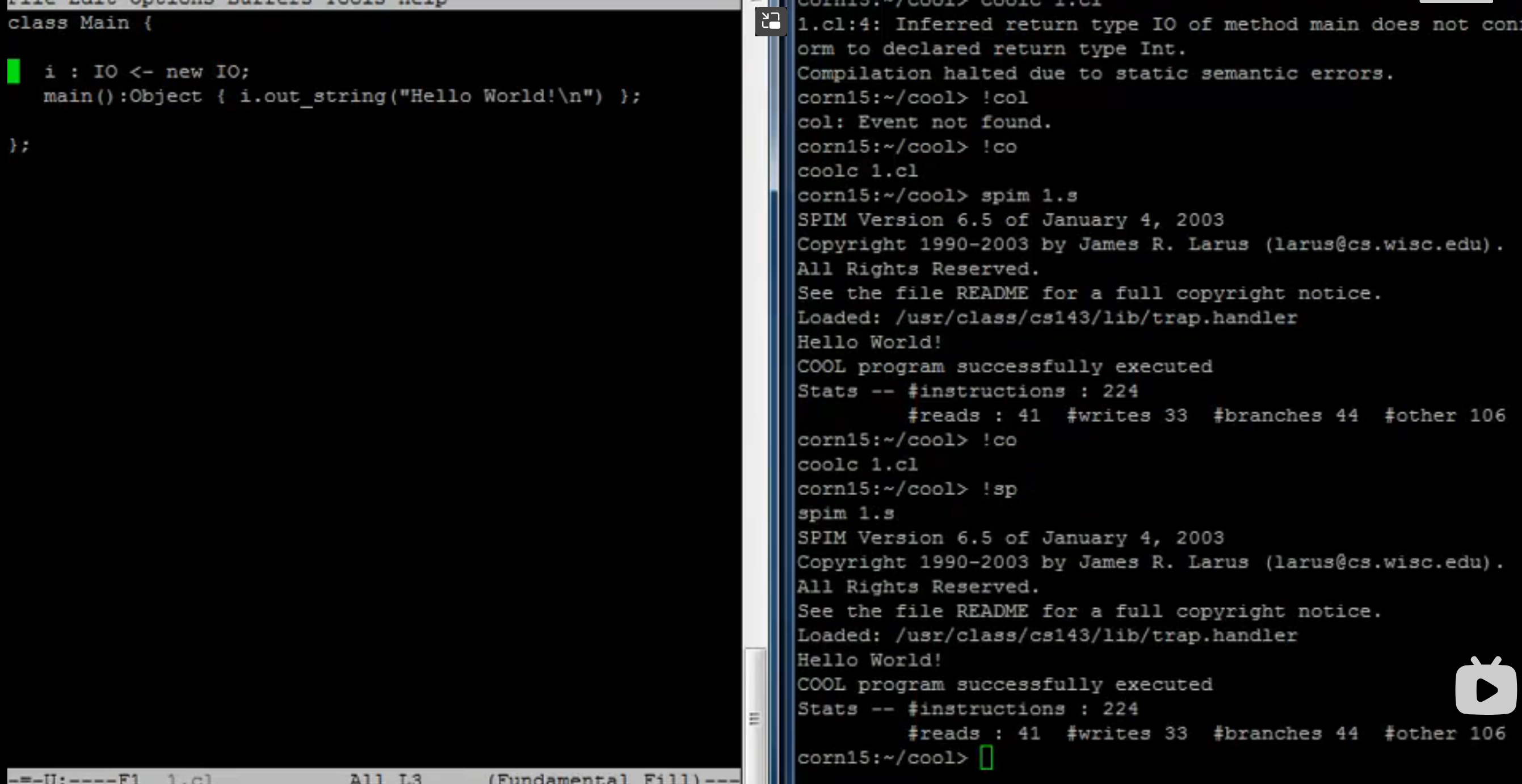
-
继承
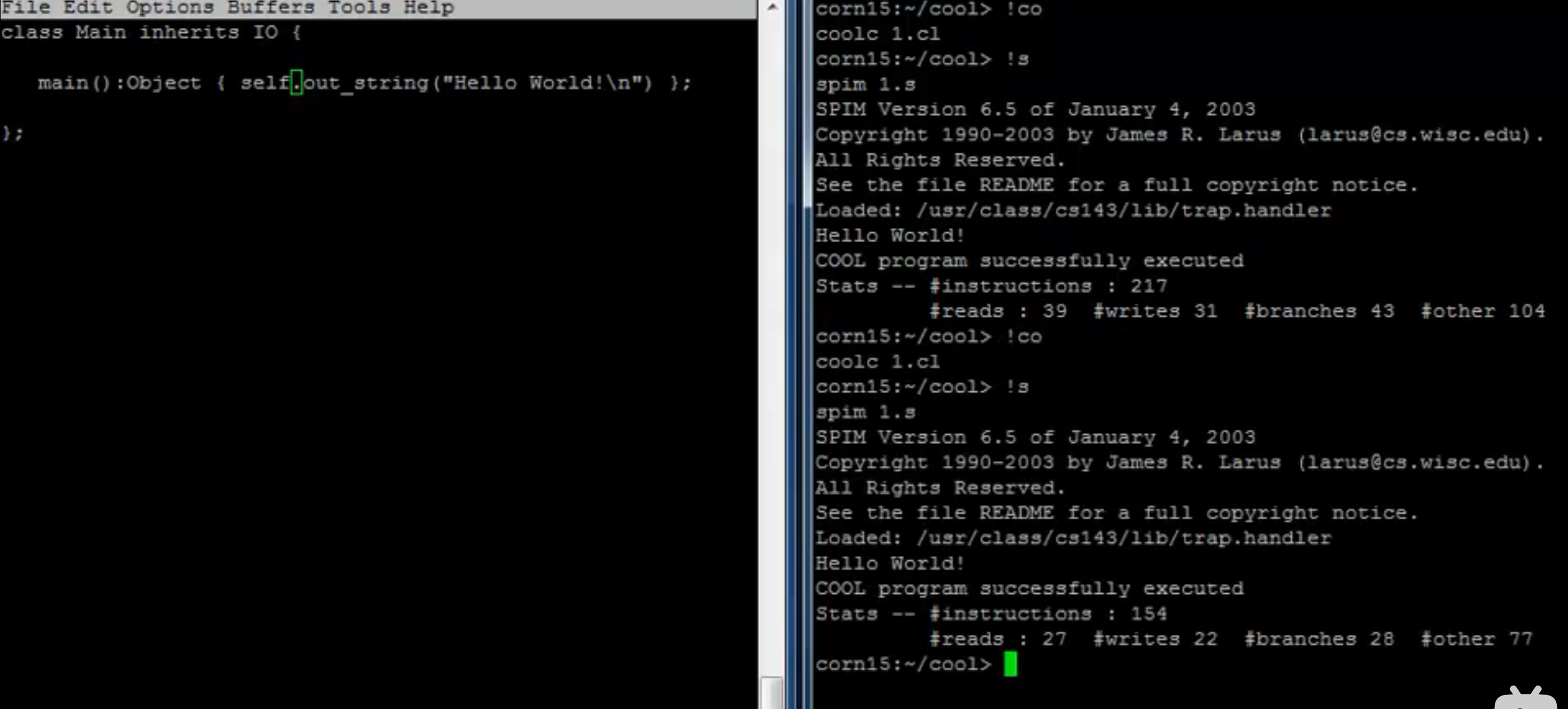
-
递归和递推
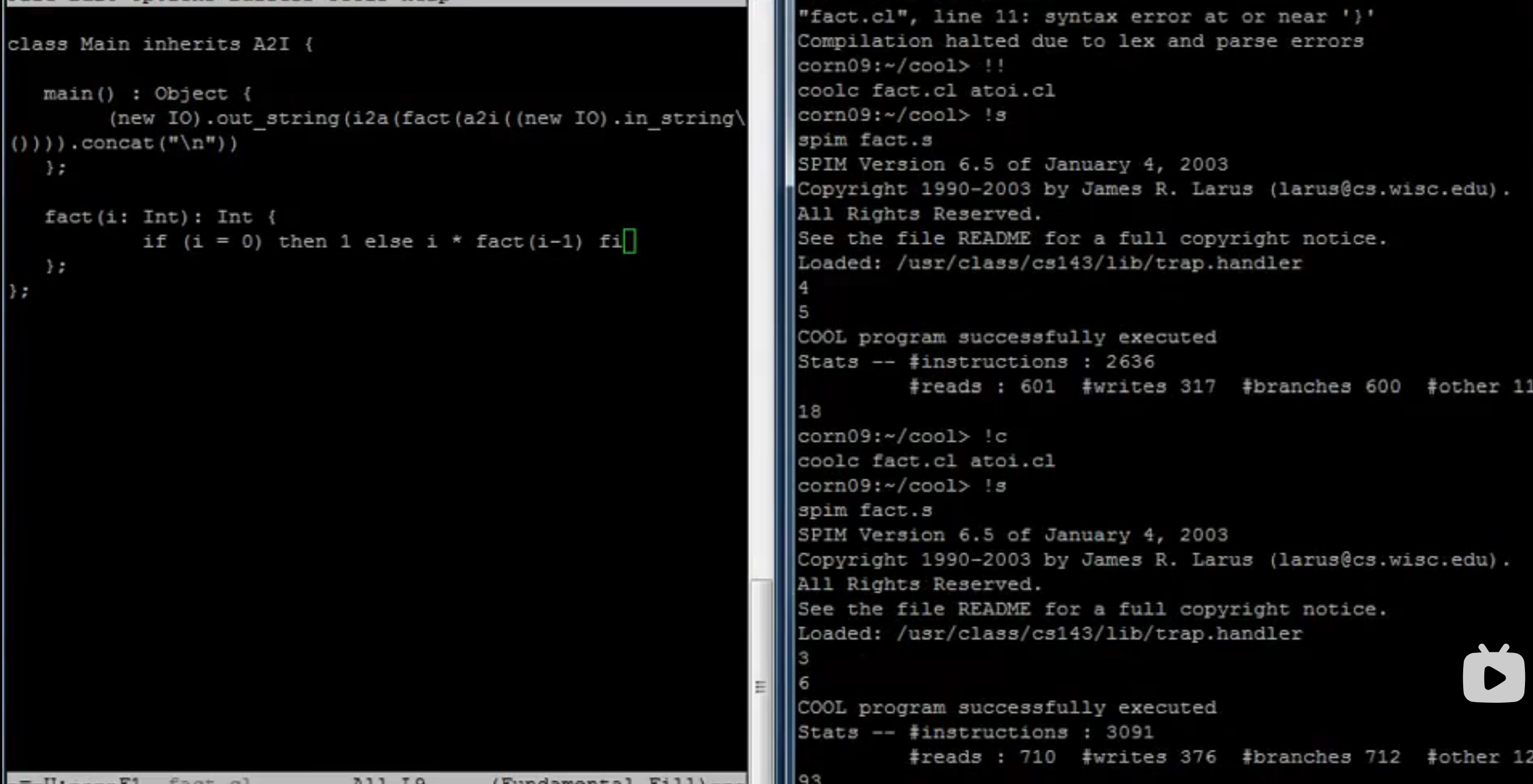
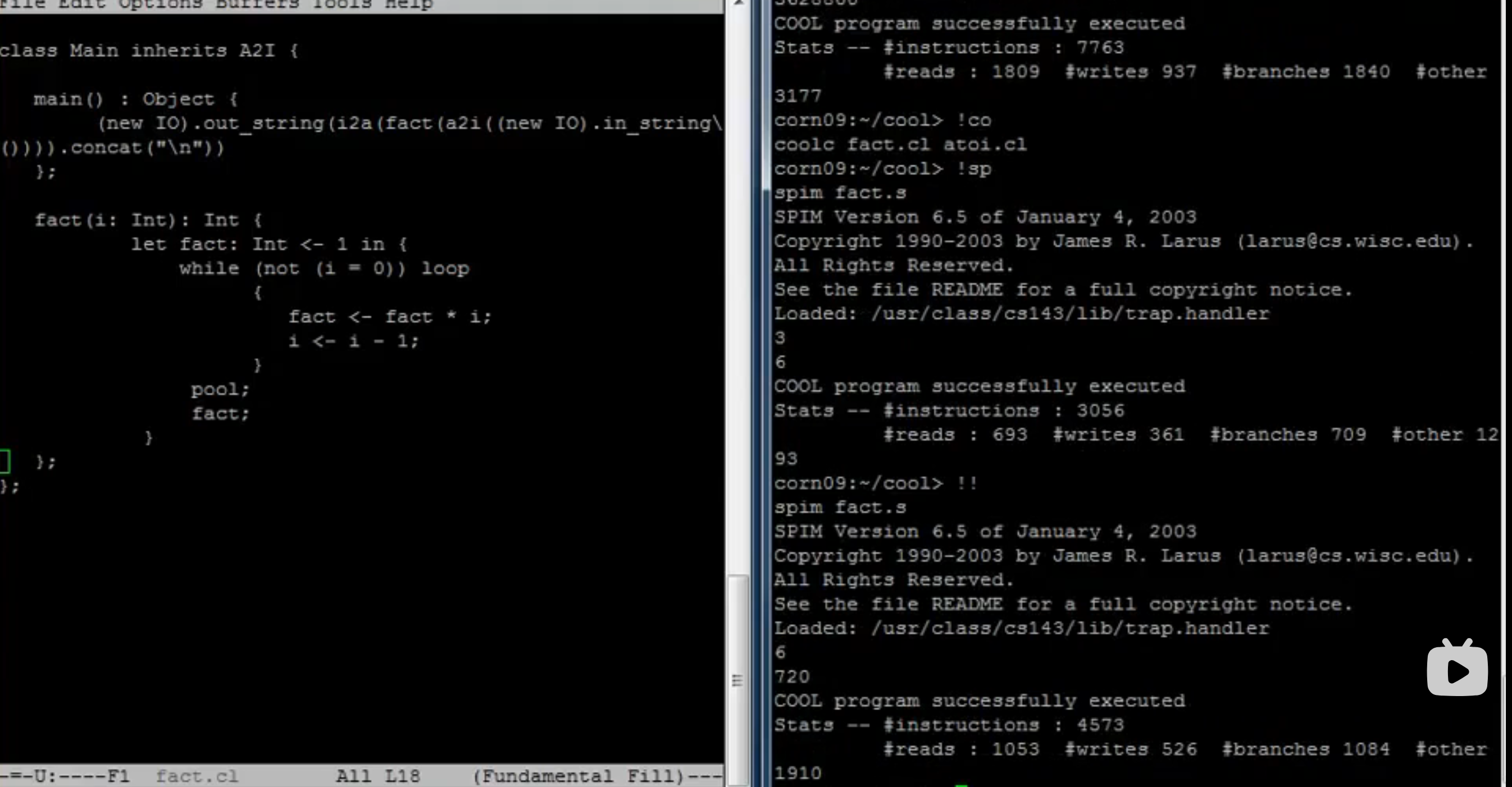
-
init 函数

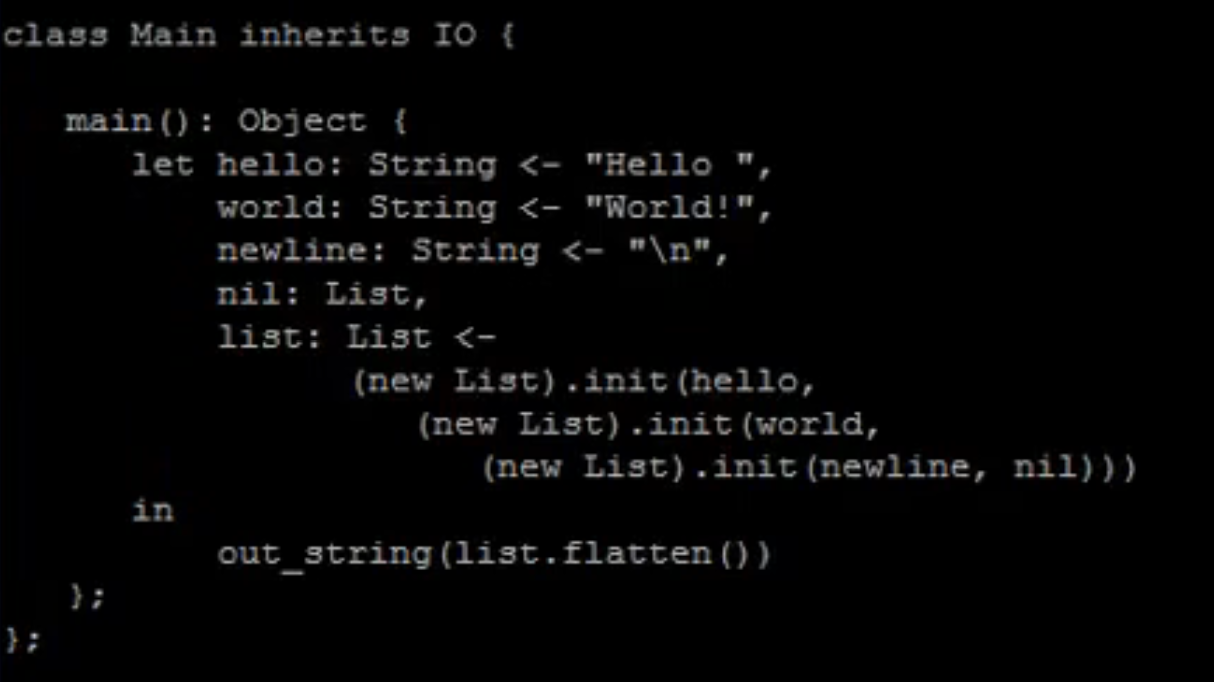
-
一些特性 (用 Object 模拟泛型)

环境配置
这个的环境配置还是很简单的, 官方是提供了一个系统镜像
-
根据自己电脑版本下载Virtual Box 并安装
-
下载系统镜像 (这里可能需要一点魔法)
-
点击镜像中的
.vbox文件直接运行即可
-
进入到桌面, 打开终端 (左下第四个图标) 进行测试
-
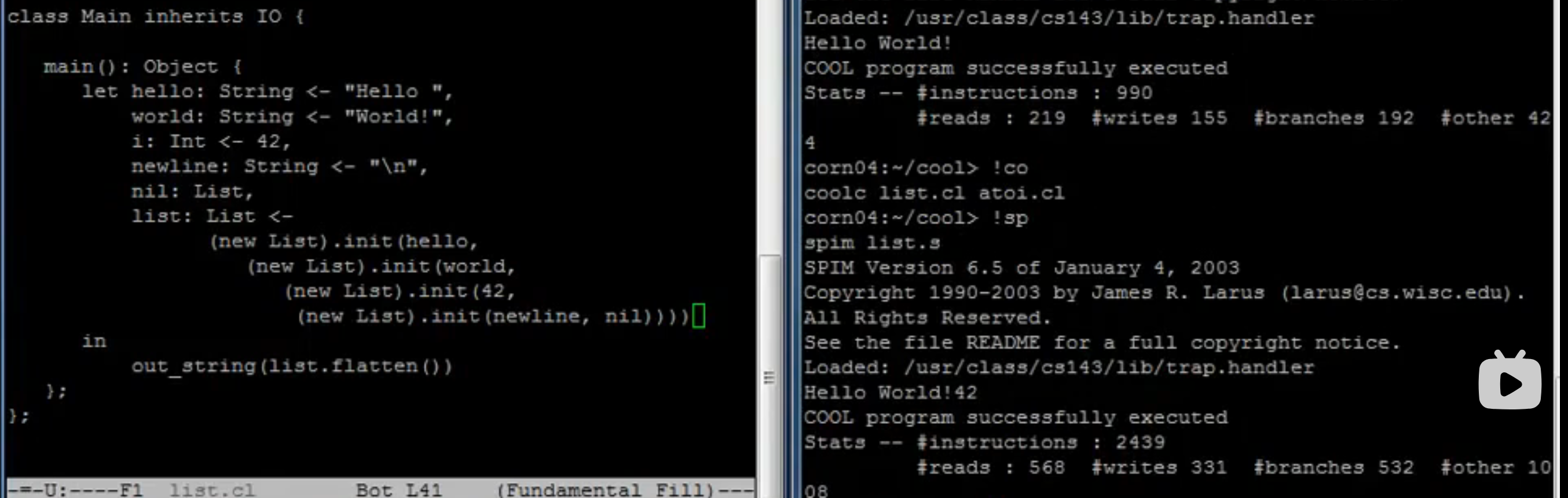
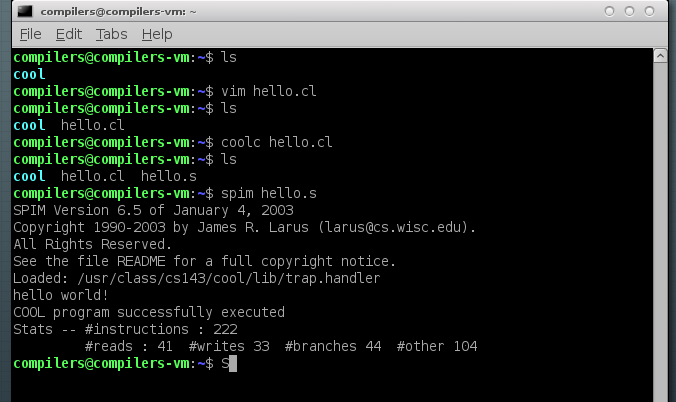
写个 hello.cl,
coolc编译出 hello.s,spim执行 hello.s
-
测试成功
Lexical Analysis
Lexical Analysis
每个lexeme被分为不同的token classes

词法分析器接收, 生成类似于键值对的 token 二元组 <type - value>, 然后发送给解析器
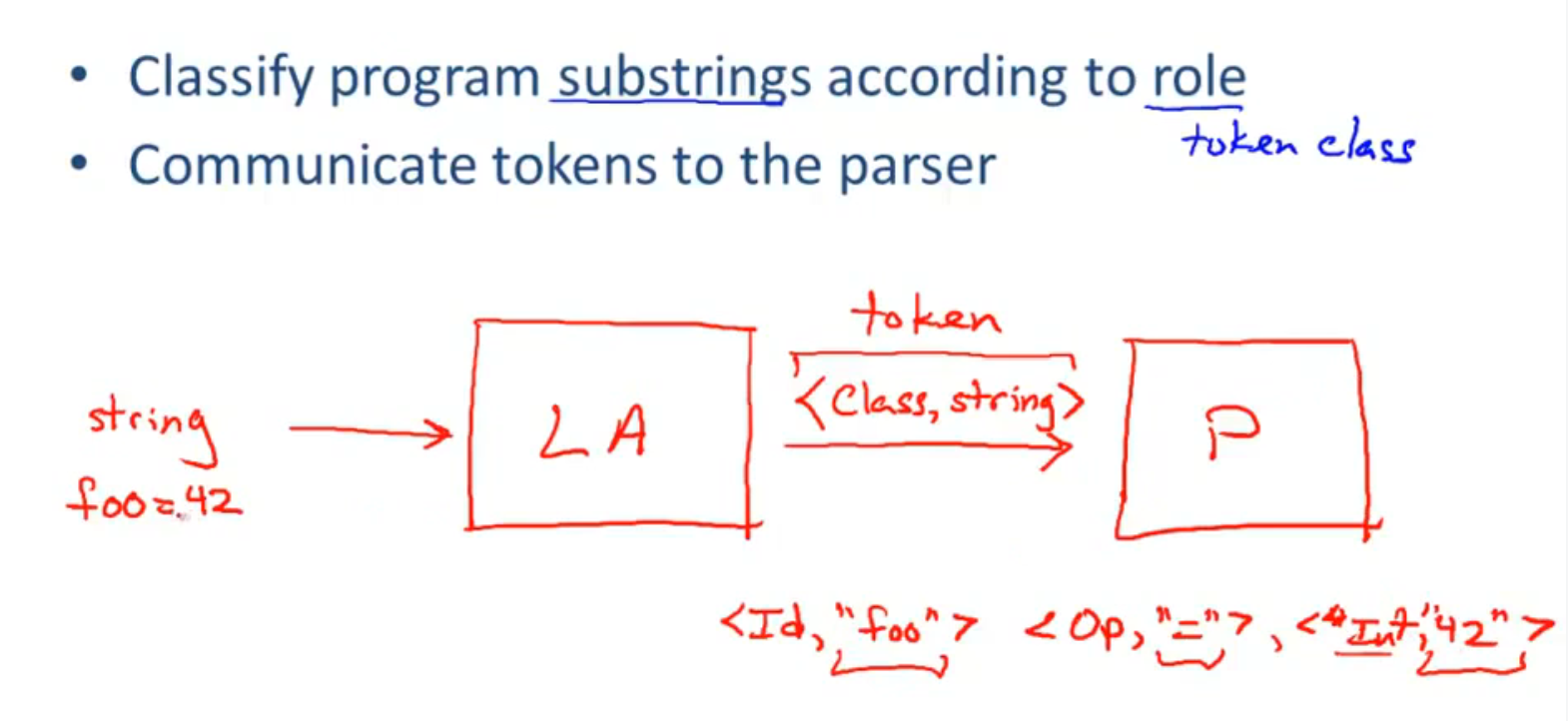
过程总结:

Lexical Analysis Examples
Fortran 的一个例子 (因为历史原因, Fortran 中的空格不重要):
DO 5 I = 1,25 // 从此句到有标签 5 的句子做循环, I 是变量, 从 1 加到 25
DO 5 I = 1.25 // 声明一个变量 DO5I, 值为 1.25
在词法分析中虽然会扫描到关键字 DO, 但只有扫描到后面的 , 才能确定这是循环的关键字

lookahead: 根据后面的词语来确定当前词语的作用
Regular Language

总而言之, 正则语言是一个强大的工具
Formal Language


将语义和语法分离, 不同语法会有相同语义, 二者之间的映射关系必须是多对一
Lexical Specifications

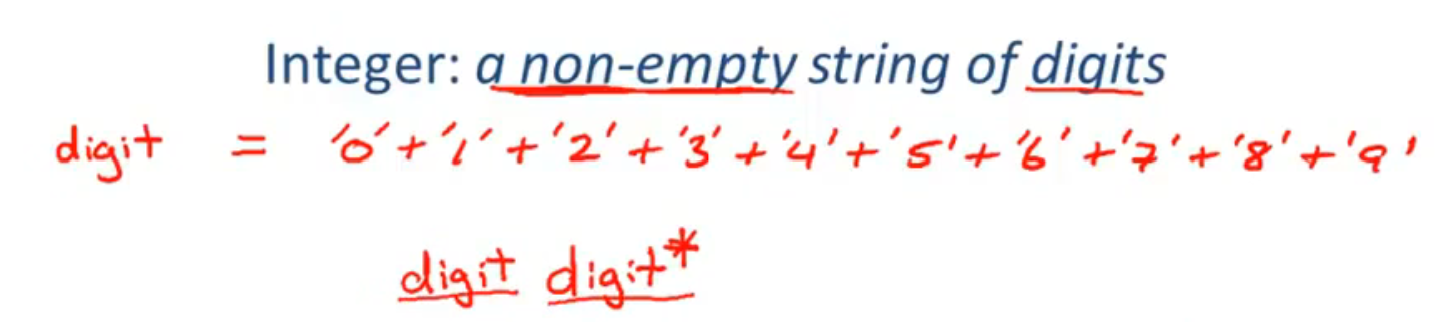


Implementation of Lexical Analysis
Lexical Specification

- 对于每个表达式用正则去匹配;
- 如果匹配到了多个正则, 则按照优先级进行识别; 如果没有则判断为一个错误
Finite Automata
基本介绍:

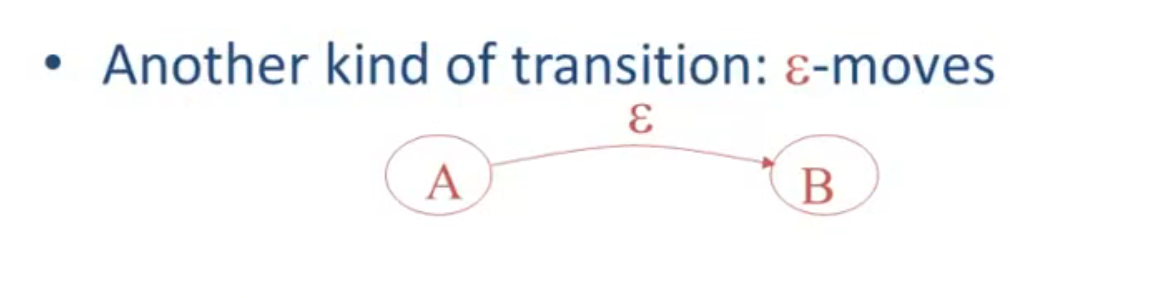
DFA 和 NFA:



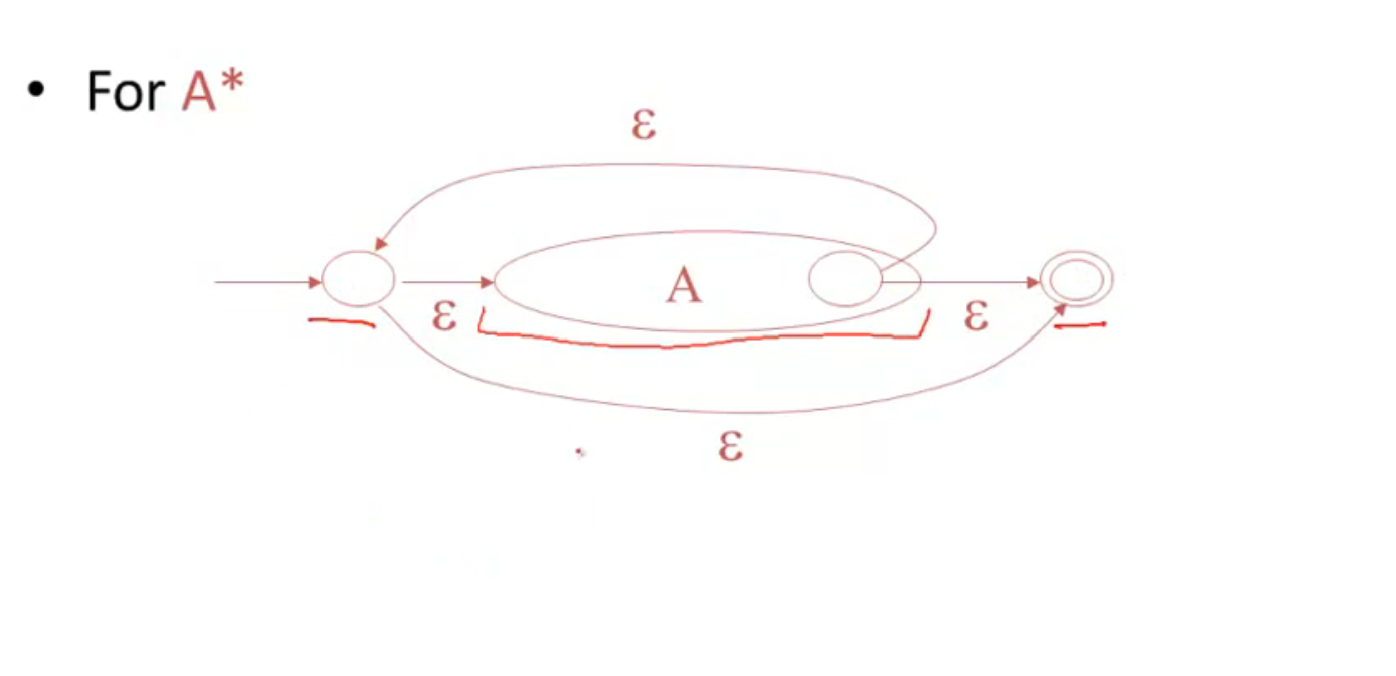
Regular Expressions into NFAs
词法分析器:
转换示例:


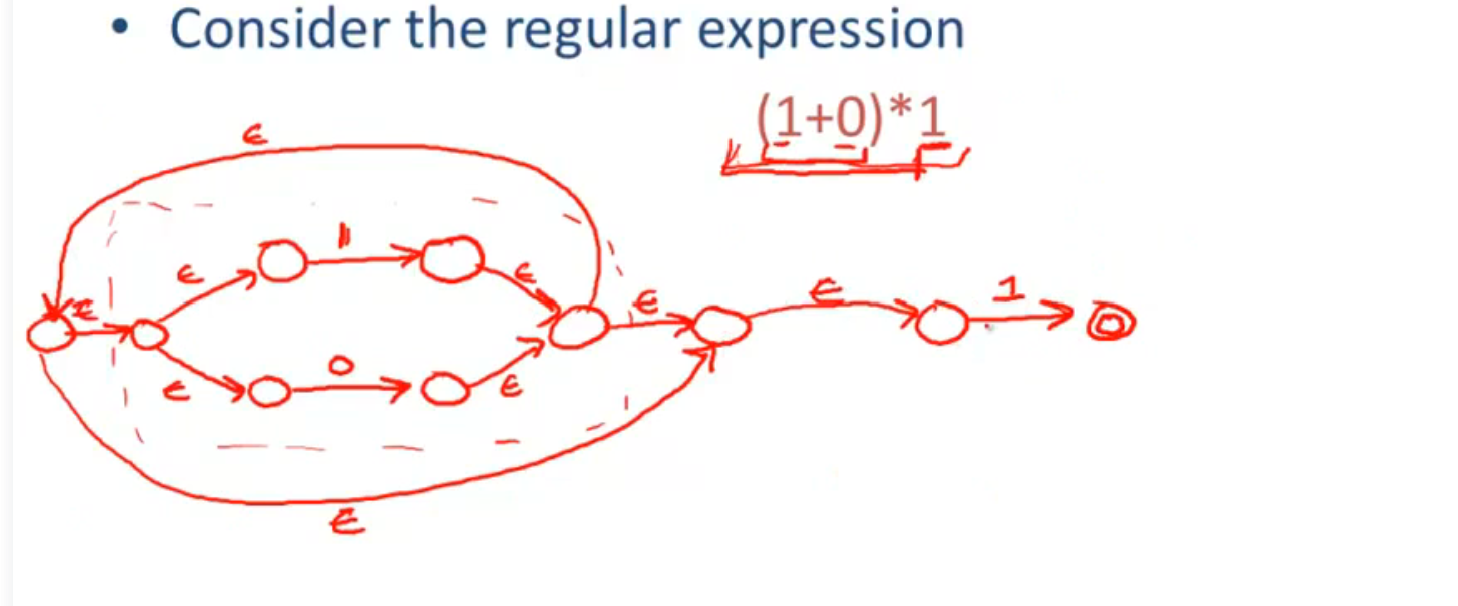
一个例子:
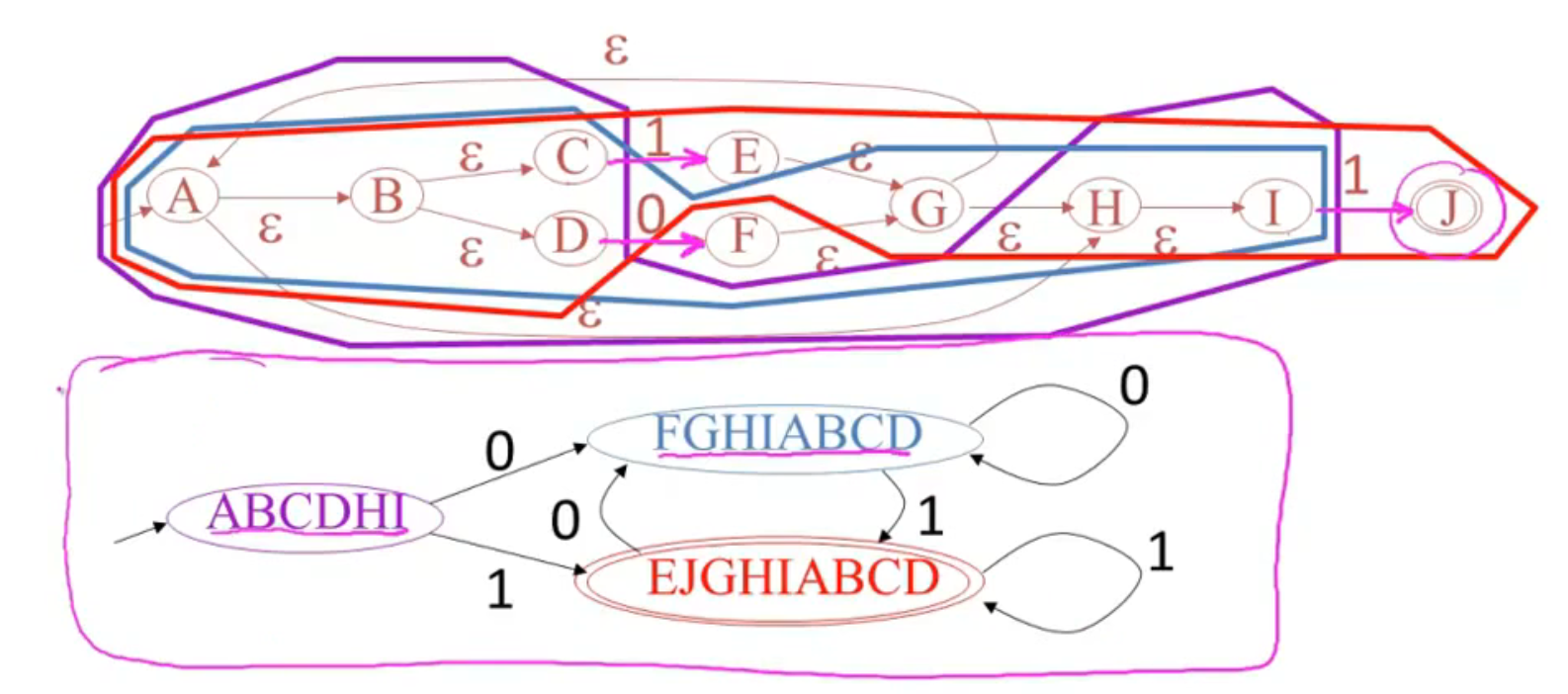
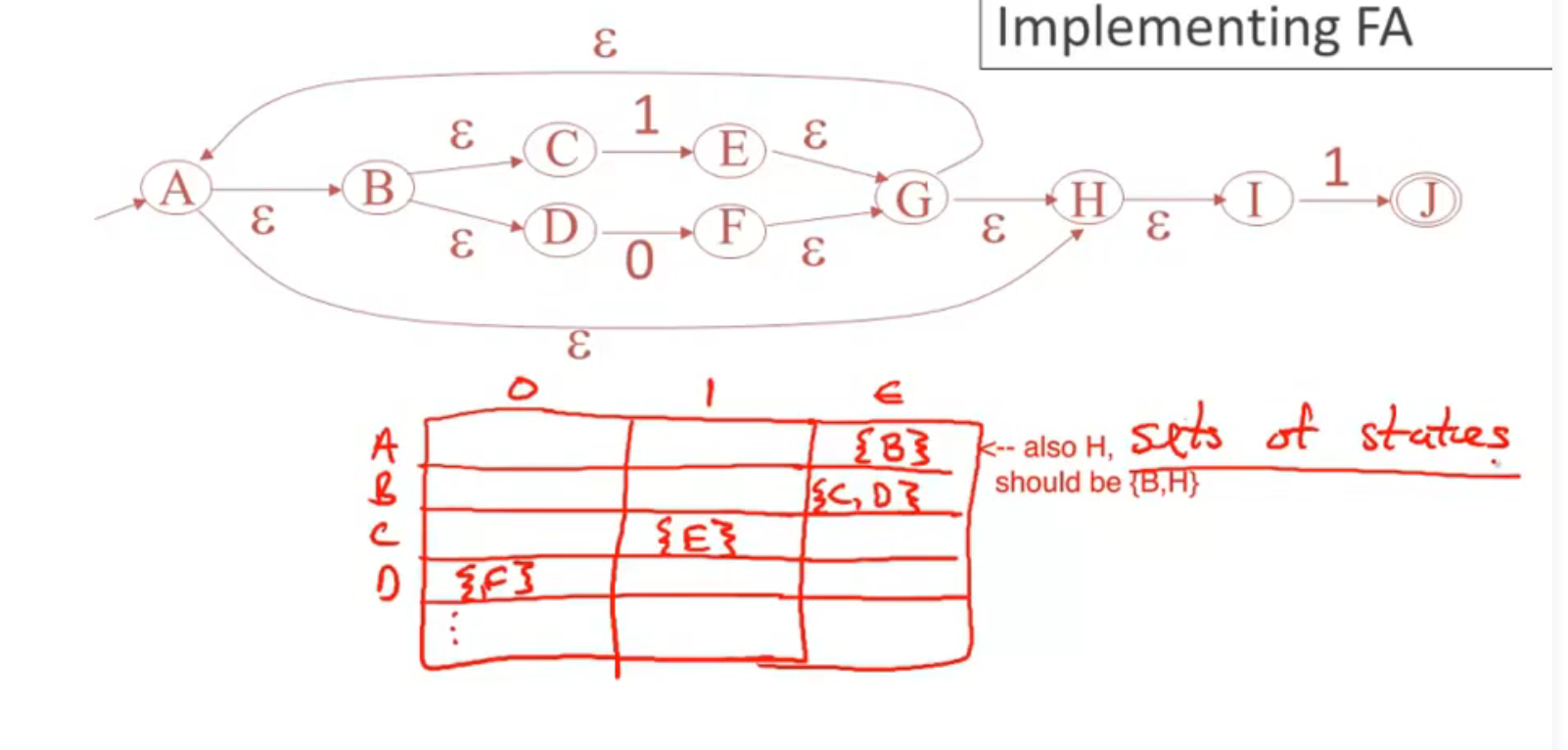
NFA to DFA
方法:

例子:
Implementing Finite Automata
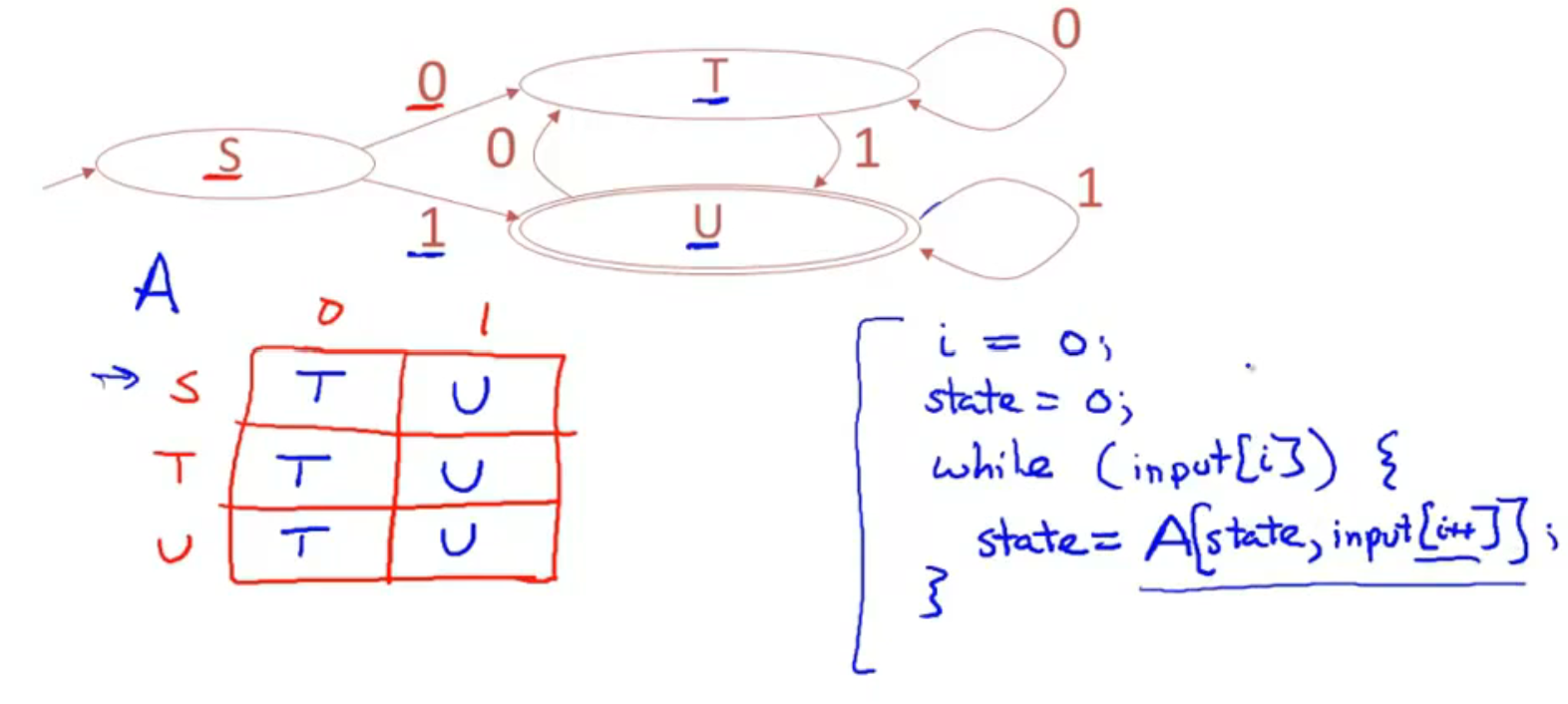
优化一下 (压缩空间):
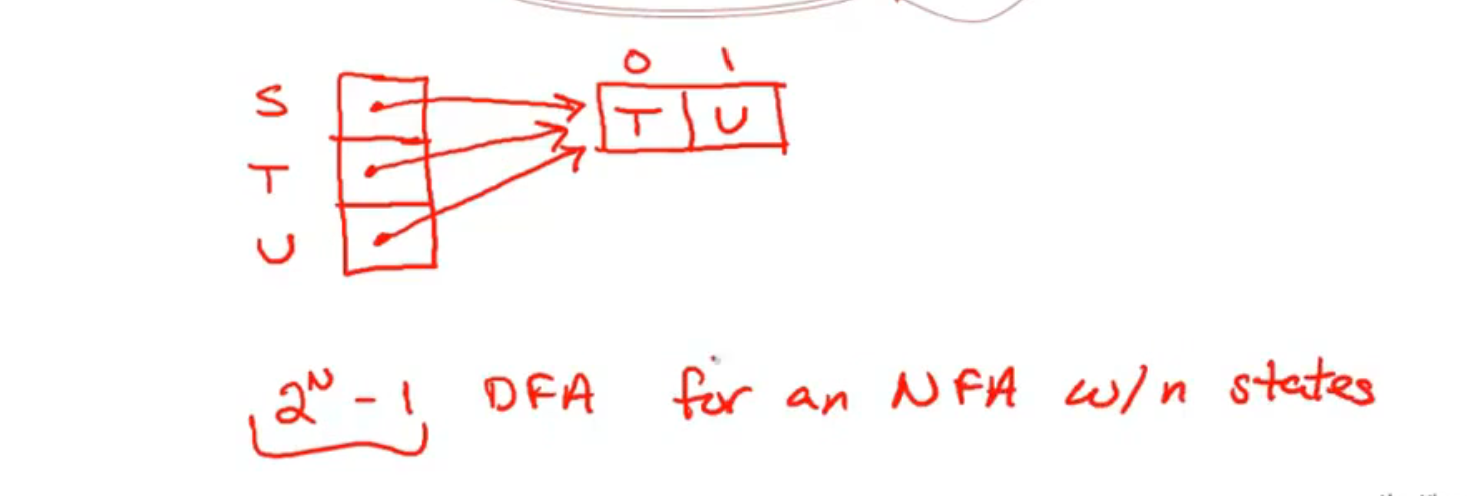
NFA 需要对每个状态都进行一次搜索, 所以就很慢:
DFA 和 NFA 的权衡:
| DFA | faster | less compact |
| NFA | slower | concise |
Introduction to Parsing
Introduction to Parsing
Parsing:

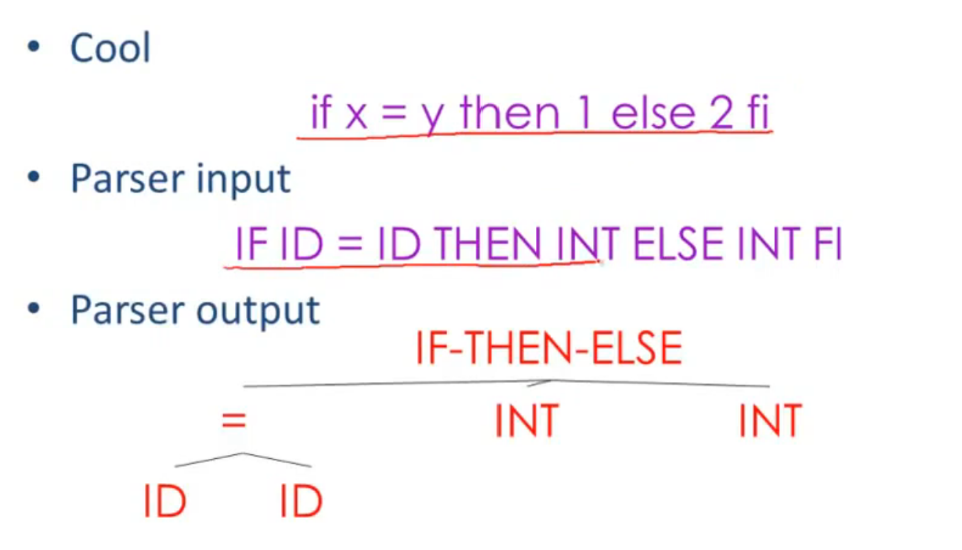
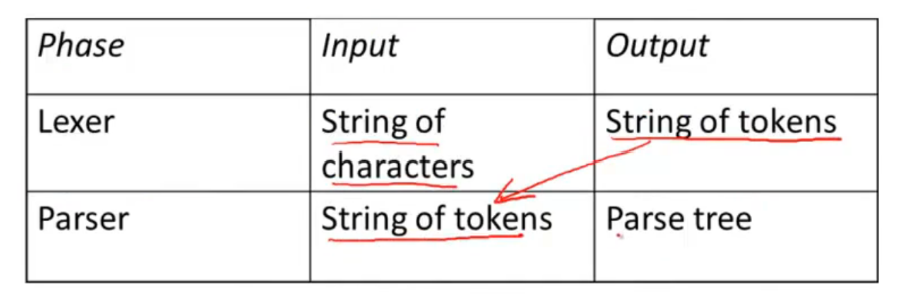
Context Free Grammars


Derivations
Parse Tree:

最左推导:

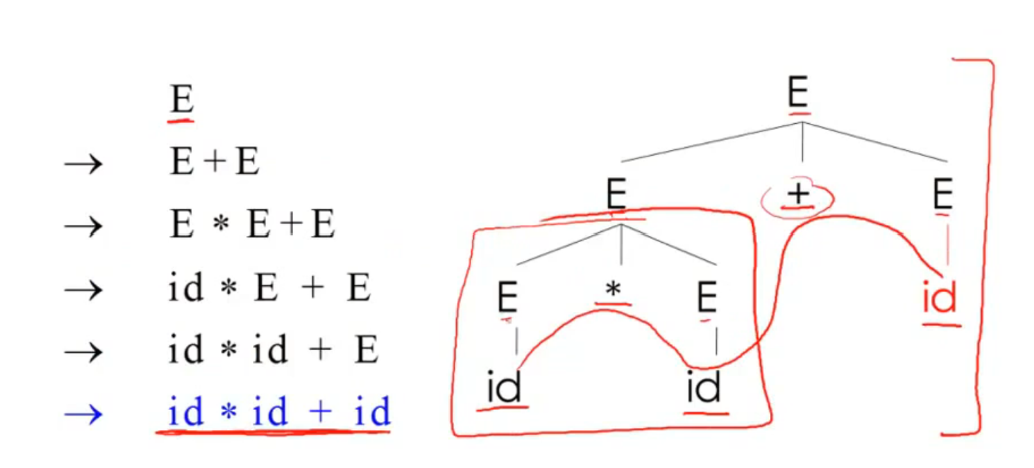
最右推导:
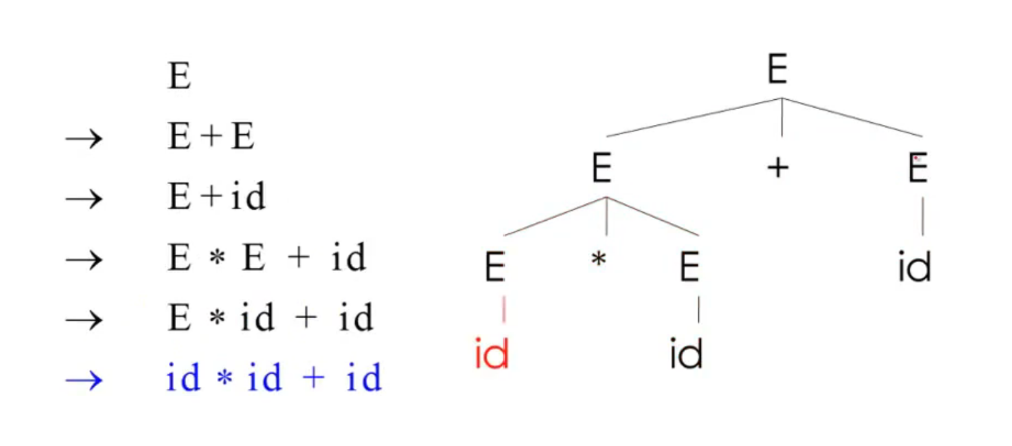
Ambiguity

Syntax-Directed Translation
Error Handling
error kinds:

error detect:


error correction:

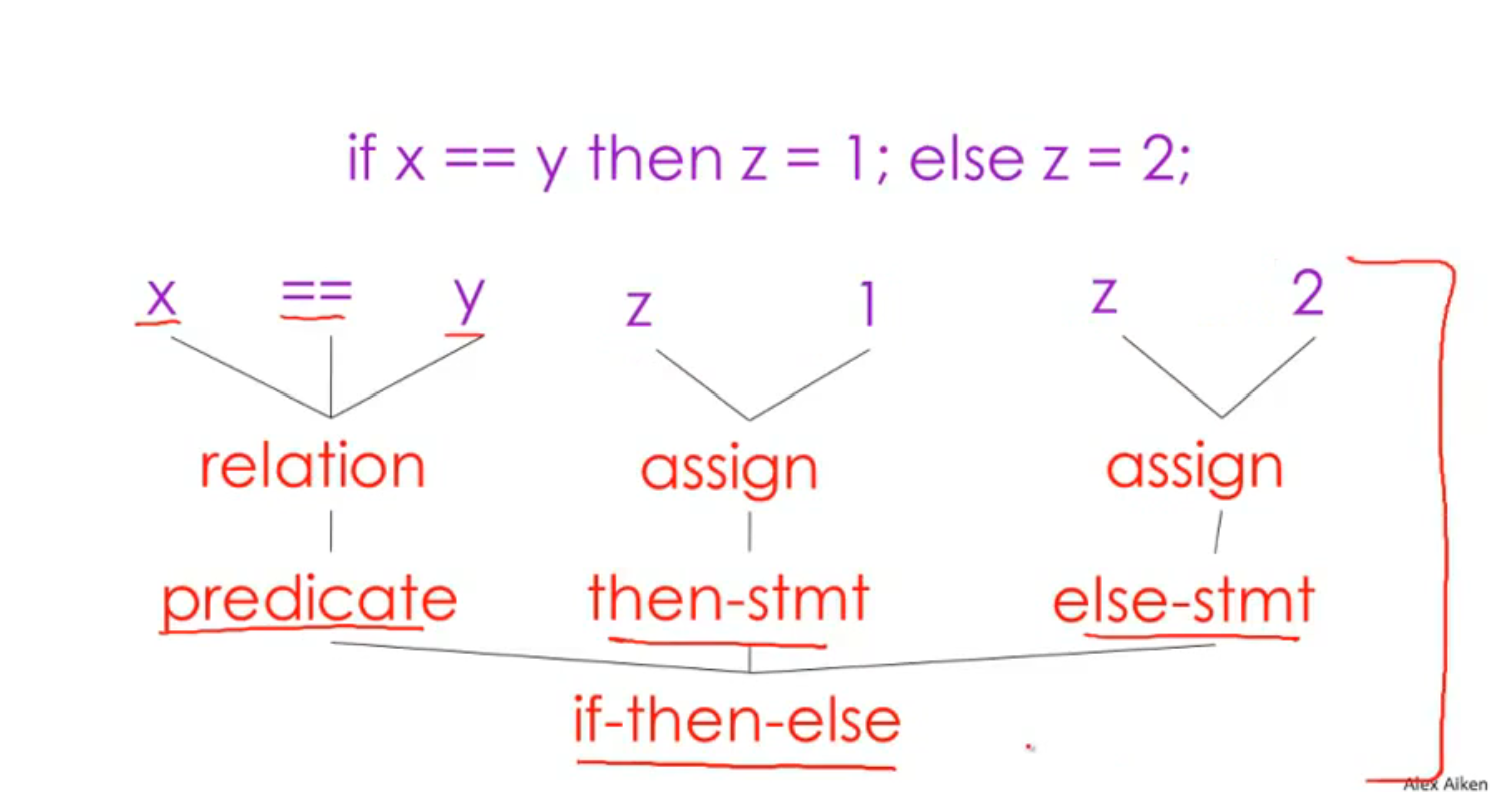
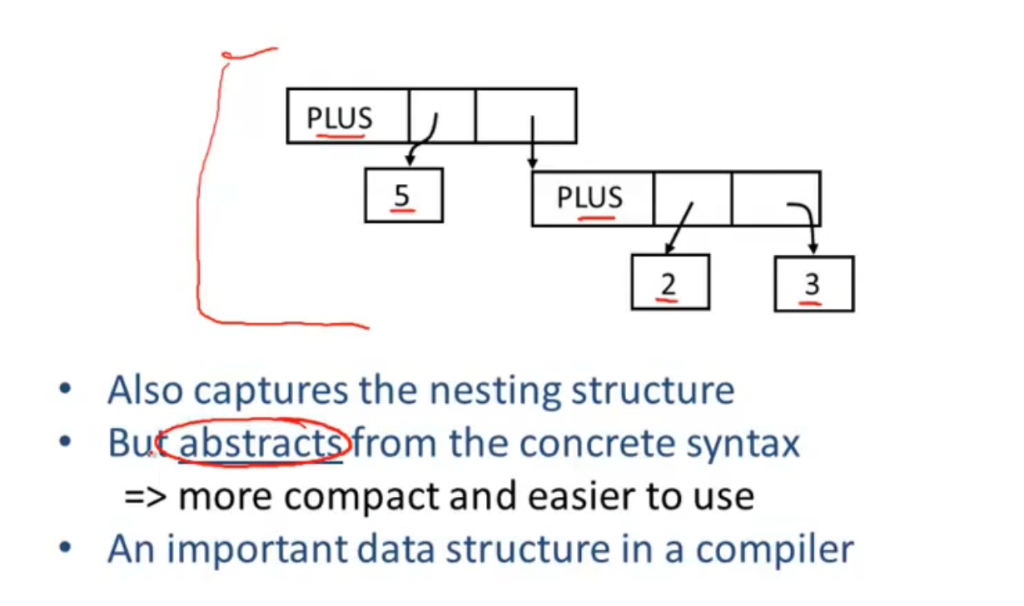
Abstract Syntax Trees

正常的语法树:
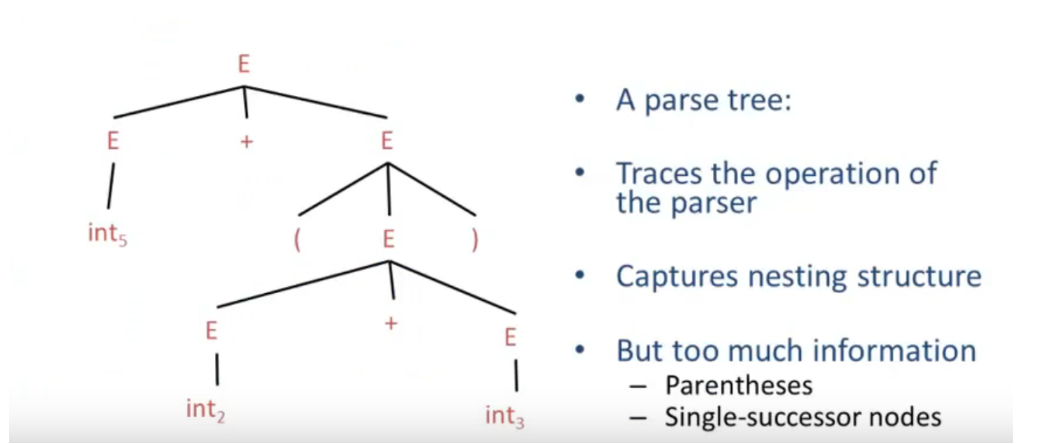
AST(Abstract Syntax Tree):
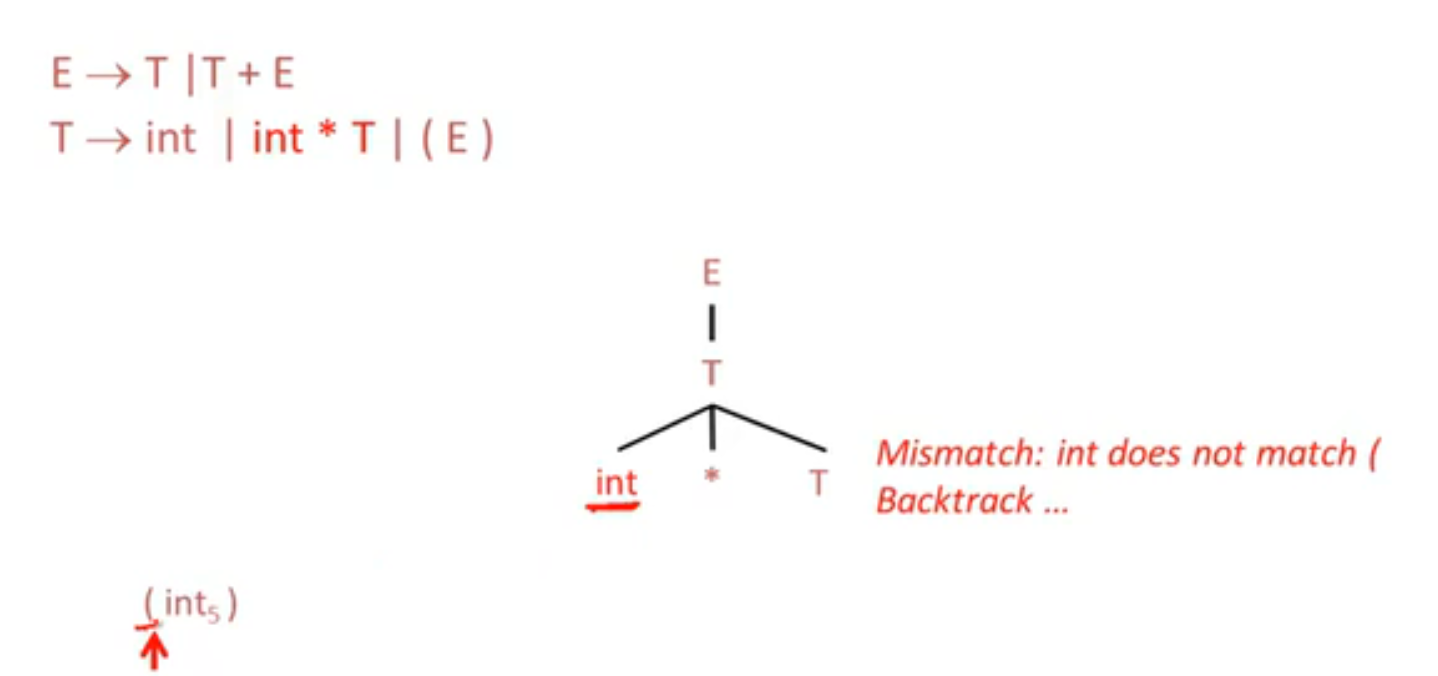
Recursive Descent Parsing
不匹配, 回溯:
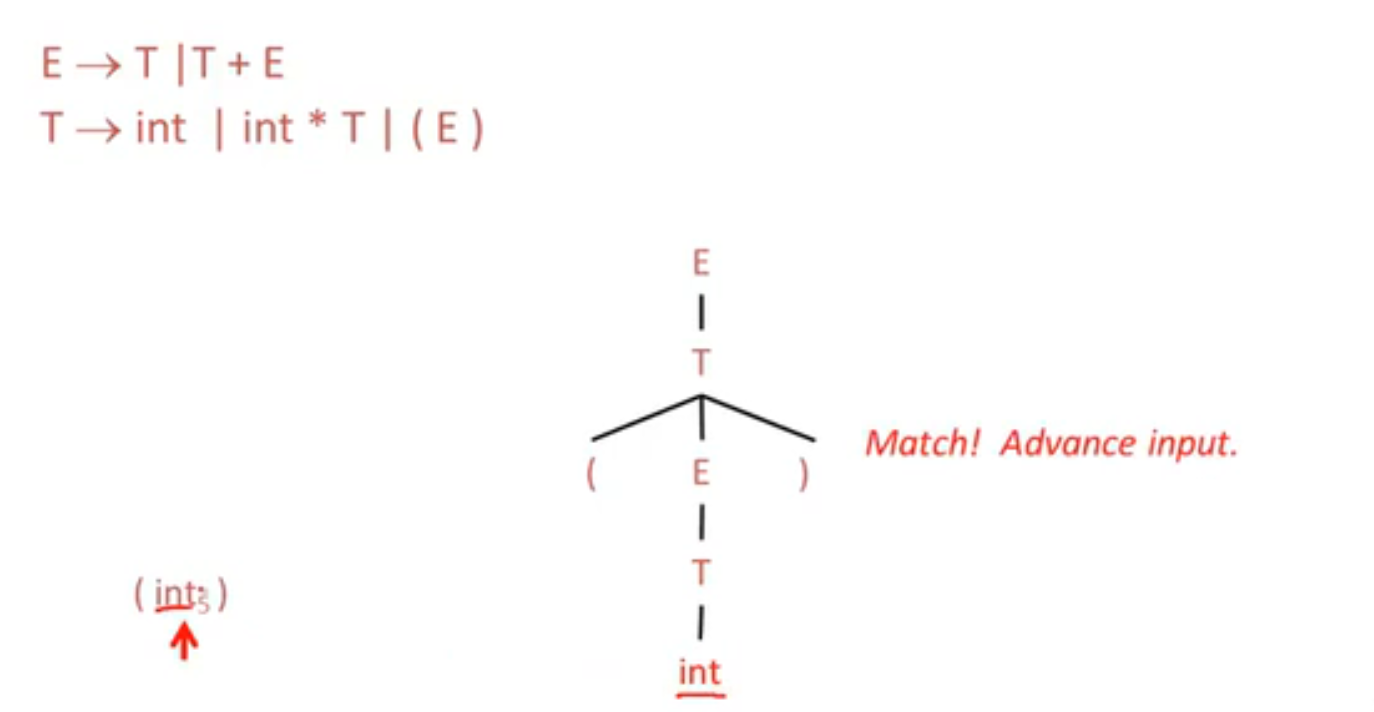
匹配成功:
Recursive Descent Algorithm
从上到下, 从左到右


一个完整的例子, 实际上整个过程就是 dfs:

Recursive Descent Limitations
没有遍历所有情况, 所以可能会有提前识别的风险

如上图, int * int 在被识别到第一个 int 后, 指针后移, 于是变成了识别 int 和 * int, 识别错误
Left Recursion
Recursive Descent Algorithm 是从左到右进行分析, 而左递归是从右到左产生语言, 无法使用该算法分析, 所以要将左递归转换为右递归

转换方法:

总结:

Top-Down Parsing & Bottom-Up Parsing I
Predictive Parsing

LL(K): 从左到右扫描, 最左生成, 向前看 K 个 tokens(此章节中 K=1)
像之前的 $T \rightarrow T+E | T$ 的例子中, $T+E$ 和 $T$ 的第一个 token 相同, 所以无法用 LL(1) 语法预测, 所以引入了 left-factored 语法 (提取左边的公因式):

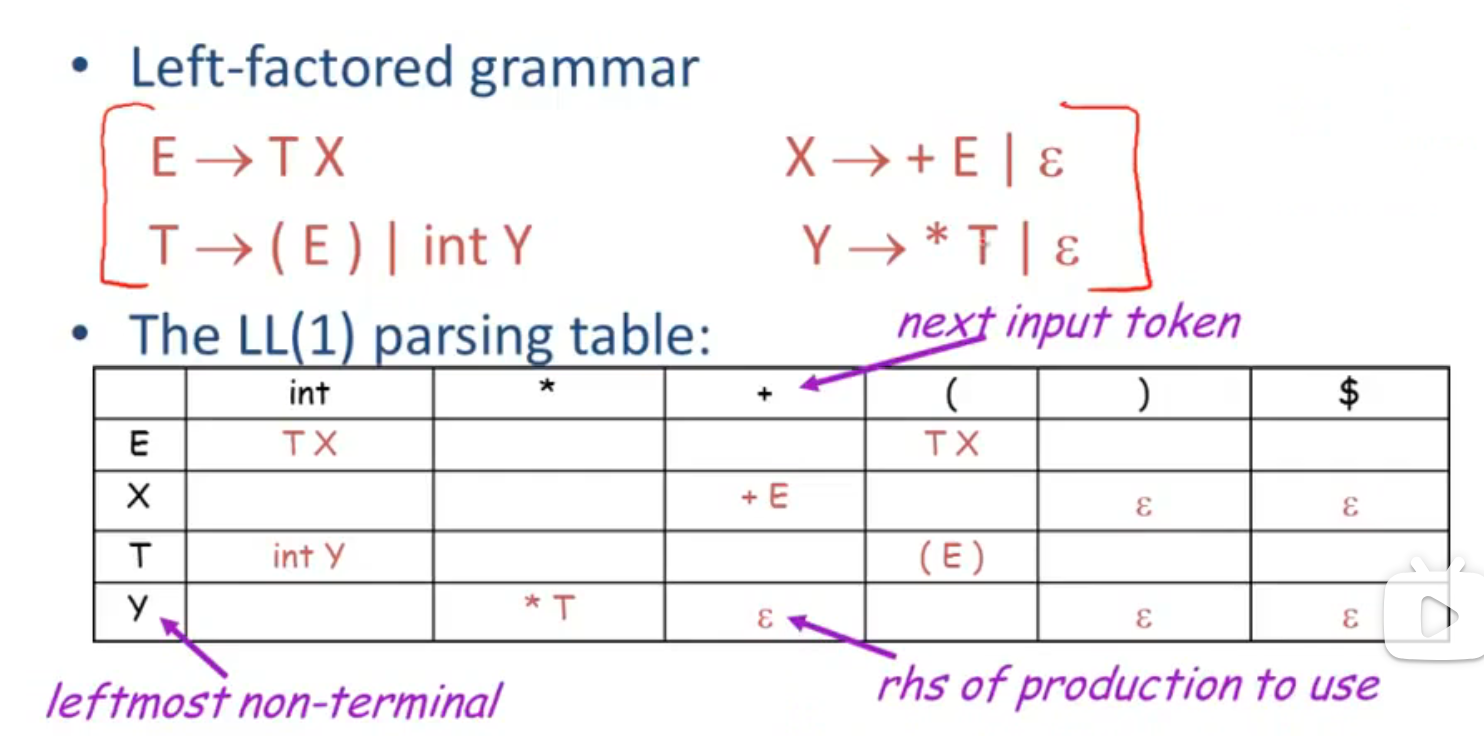
leftmost non-terminal: 最左非终结符
next input token: 下一个输入的 token
rhs of production to use: 生成式的右边部分

使用 LL(1) parsing table 的算法:


一个例子:

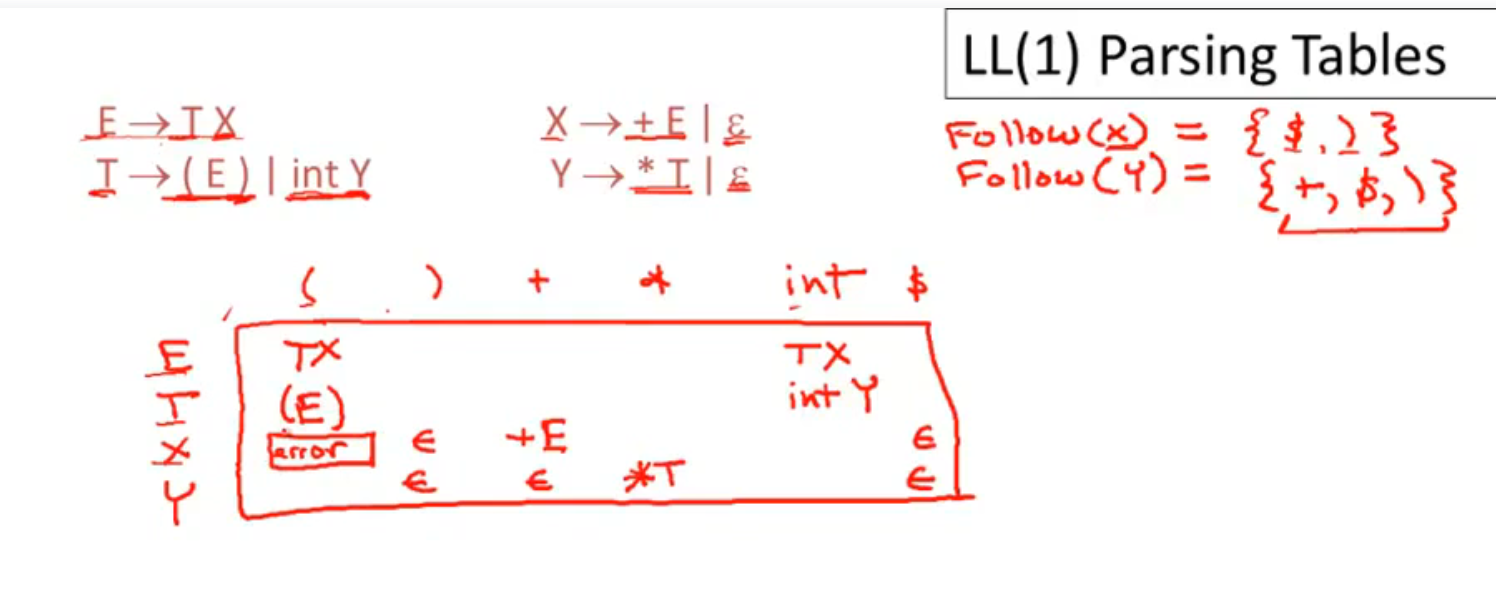
First Sets


终结符的 First Set 是他本身, 所以 $First(t) = {t} \dots$
$E$ 根据 LL(1) 会识别到 $T$, 所以 $First(E) \supset First(T) $, 但是因为 $E$ 没有生成新的 (区别于 $First(T)$ ) 终结符, 所以 $First(E) = First(T)$
Follow Sets



LL(1) Parsing Tables


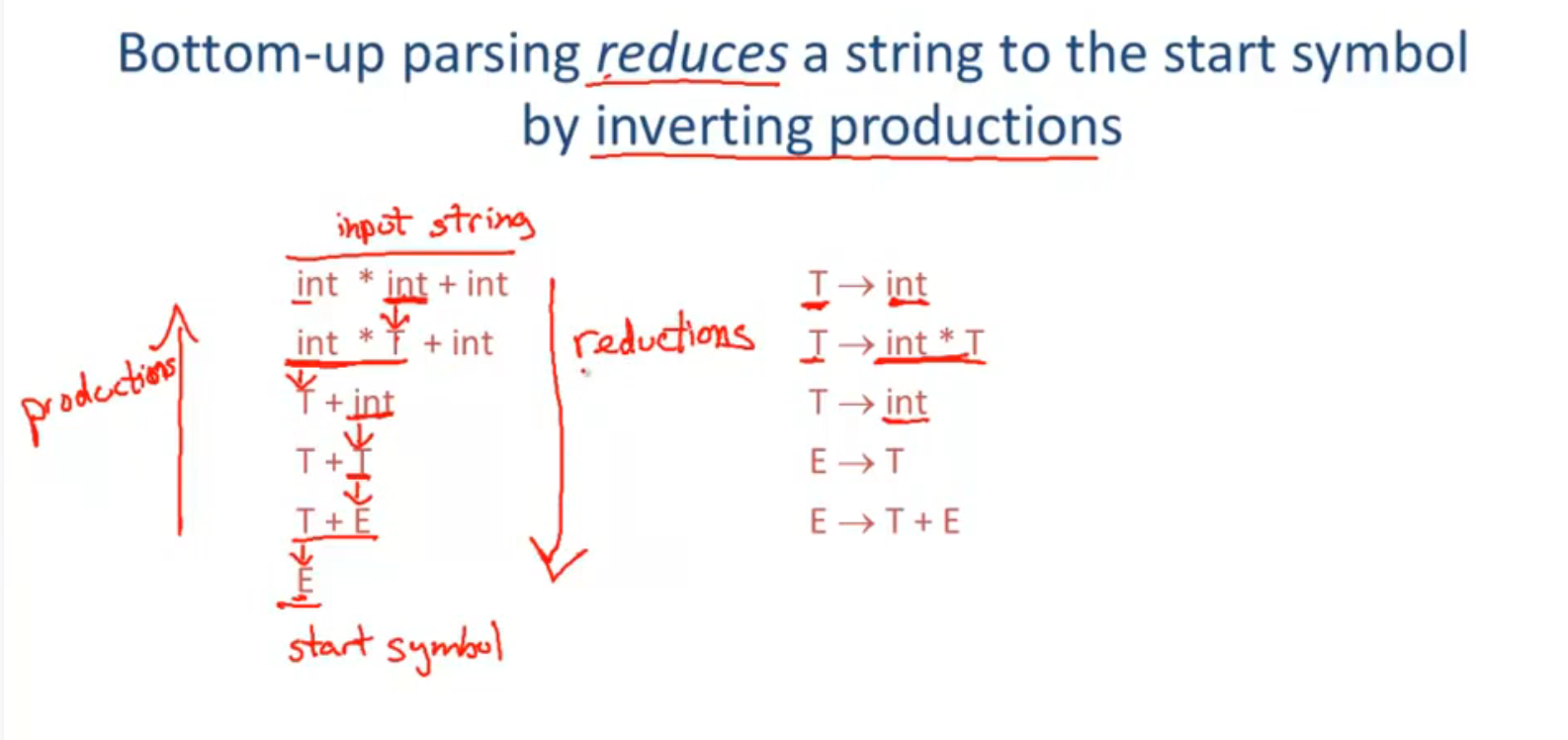
Bottom Up Parsing
rightmost derivation
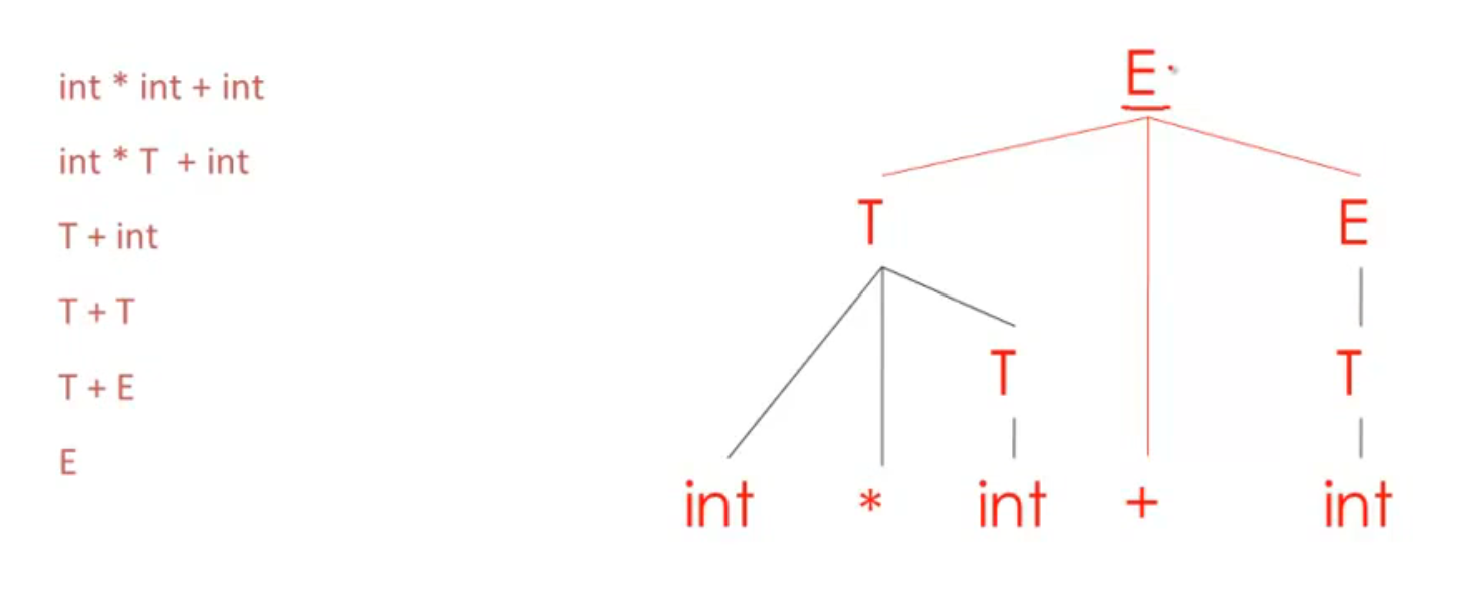
Shift Reduce Parsing

| 表示输入的位置

lhs: left hand side 推导式的左边部分
rhs: right hand side 推导式的右边部分
Bottom-Up Parsing II
Handlers


Recognizing Handlers





Recognizing Viable Prefixes


Valid Items


SLR Parsing


reduce: 规约, 生成式右到左执行
shift: 移入, 生成式左到右执行

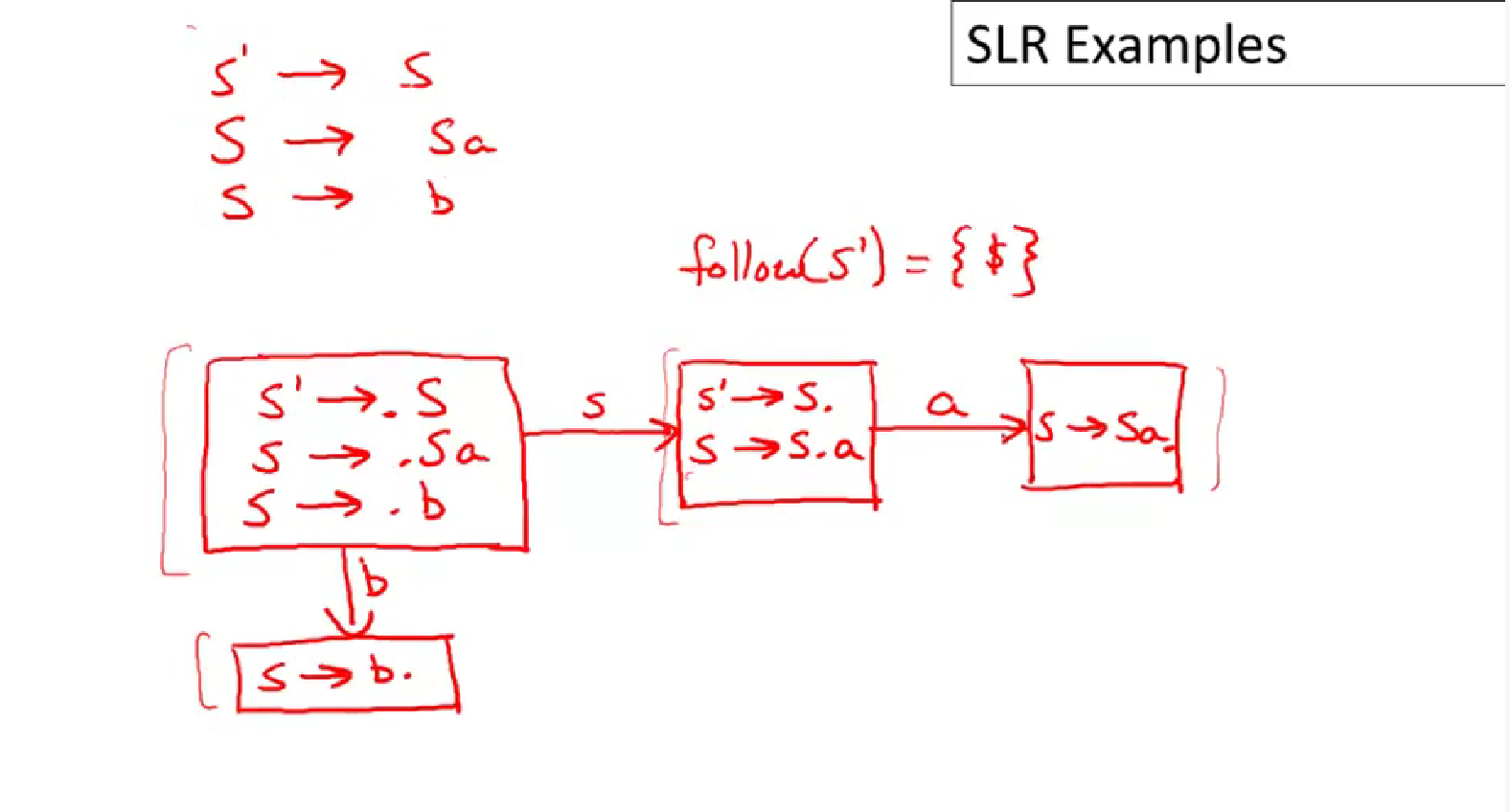
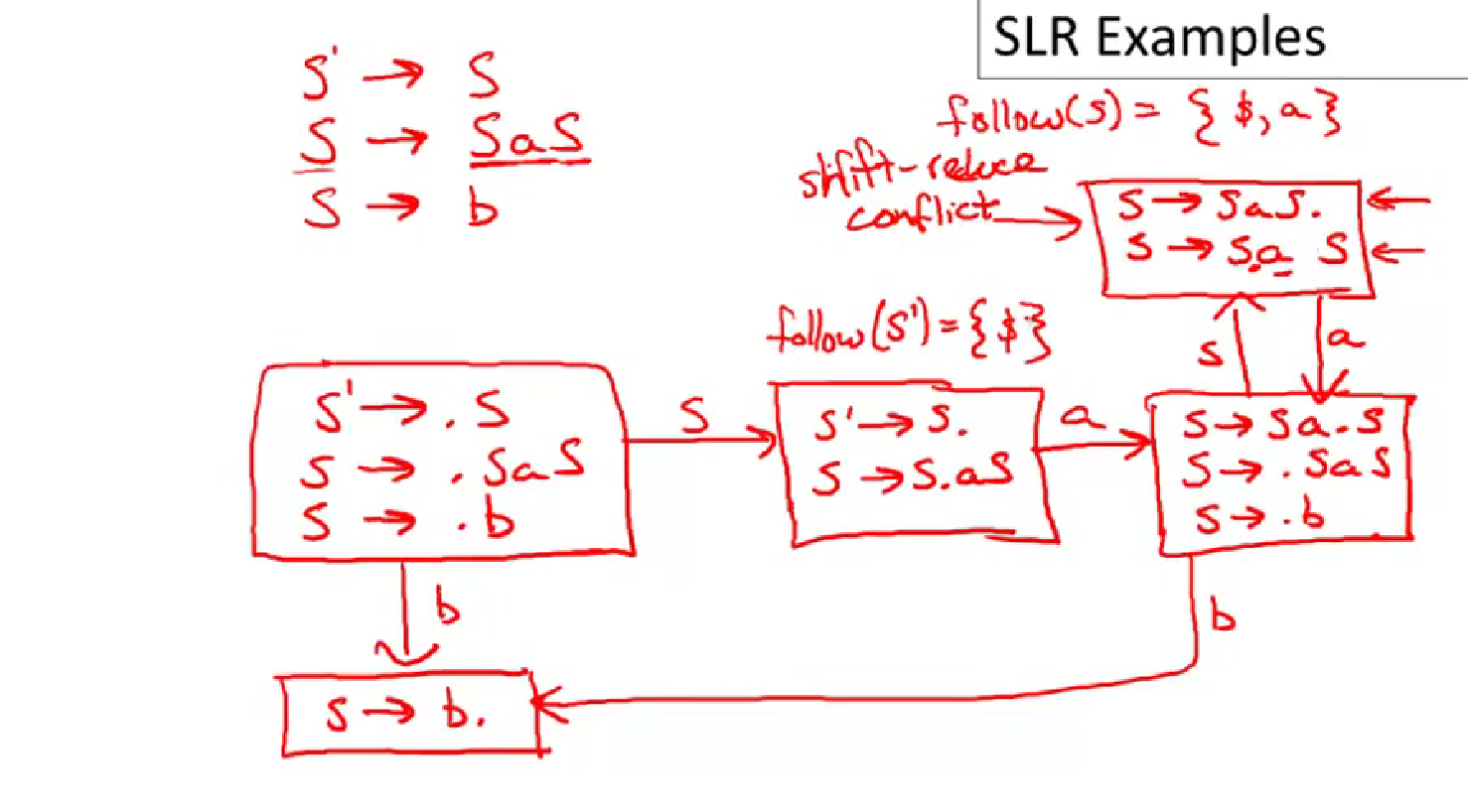
SLR Parsing Example
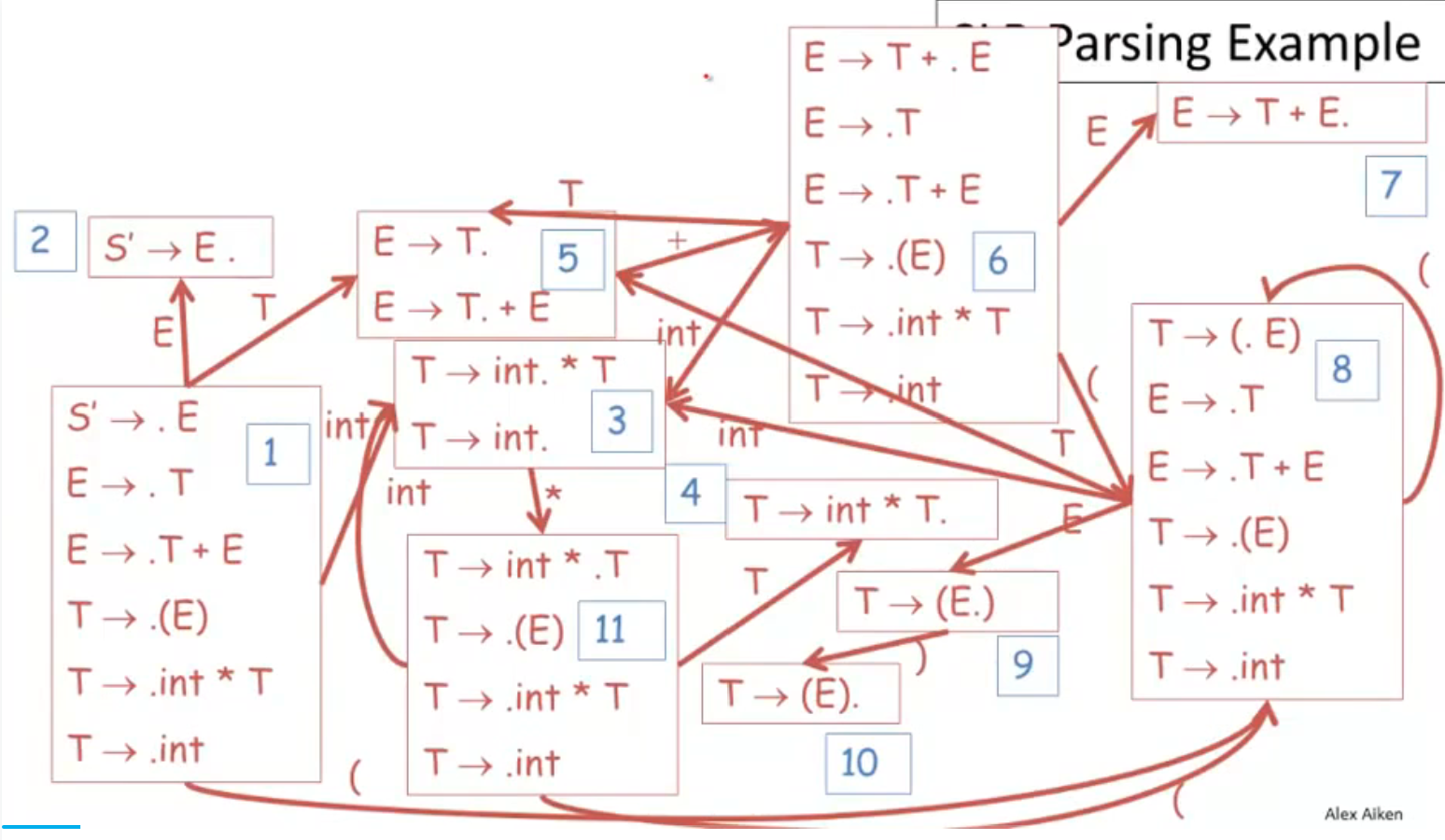

red : reduce
SLR Improvements






SLR Examples