技术概述
研究背景
随着人工智能和机器学习技术的飞速发展,处理和分析非结构化数据的需求日益增长。传统的关系型数据库在处理这类数据时存在效率低下和扩展性有限的问题。向量数据库,作为一种新型的数据库系统,专门设计用于存储、检索和分析高维向量数据,能够有效地解决这些问题。
发展现状
- 向量数据库技术不断创新,例如 Milvus 2.0 的发布,它是一款云原生向量数据库,具备高可用、高性能、易拓展的特点;
- 多个开源向量数据库产品如 Vald、Weaviate、Qdrant 等在 GitHub 上涌现,促进了技术的共享和社区的发展;
- 传统数据库厂商如 Elastic 和 Redis 也开始支持向量检索功能,表明向量数据库技术正在被更广泛地接受和应用。
应用场景
- 推荐系统:向量数据库在构建高效的推荐系统中发挥重要作用,通过支持相似性查询和向量聚合,实现对用户历史行为的分析和个性化推荐;
- 问答系统 :在智能客服、智能助手等领域,向量数据库通过存储和检索问题和答案的向量表示,提高问答系统的检索效率和准确性;
- 文本/图像检索:向量数据库在大规模文本/图像数据库中搜索相似内容的任务中展现出高效性能,尤其在图像检索等场景中,通过高性能的索引存储实现相似度计算;
- 大模型知识库:向量数据库可以与大语言模型配合使用,构建企业专属的外部知识库,为大模型提供提示信息,辅助生成更准确的答案;
- AI Native 应用:向量数据库在 AI 原生应用中扮演重要角色,如无人驾驶、NLP 等领域,通过存储和检索大规模向量数据,支持复杂的 AI 应用1。
产品介绍
基本原理
海量的非结构化数据一般会存储在分布式文件系统或对象存储上,之后通过深度学习网络完成推理,将这些非结构数据转化成 embedding 向量,并在向量空间内完成近似性检索,从而发现数据背后的一些特征2。
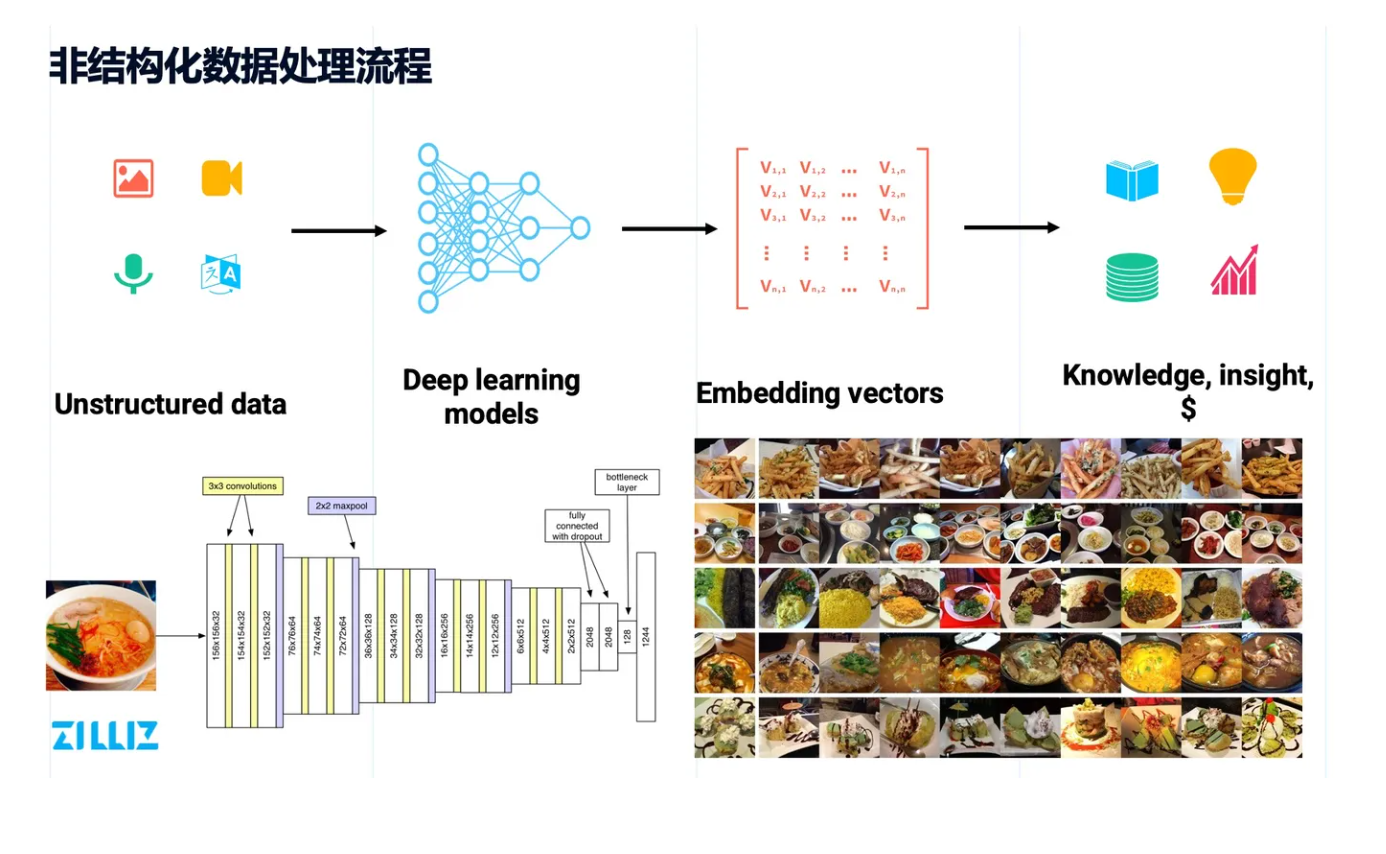
标量和向量
对于标量数据,针对数值类数据一般会做加减乘除的操作;对字符串类型的数据一般会做一些相等, 或者一些类似 like 的近似匹配。
而针对向量数据而言,很少进行这种完全匹配,更多是看近似度,也就是高维空间下的距离。较常见的距离表示有余弦距离、欧式距离等。空间中向量之间的距离,很大程度上能表示非结构化数据之间的相似度。
架构
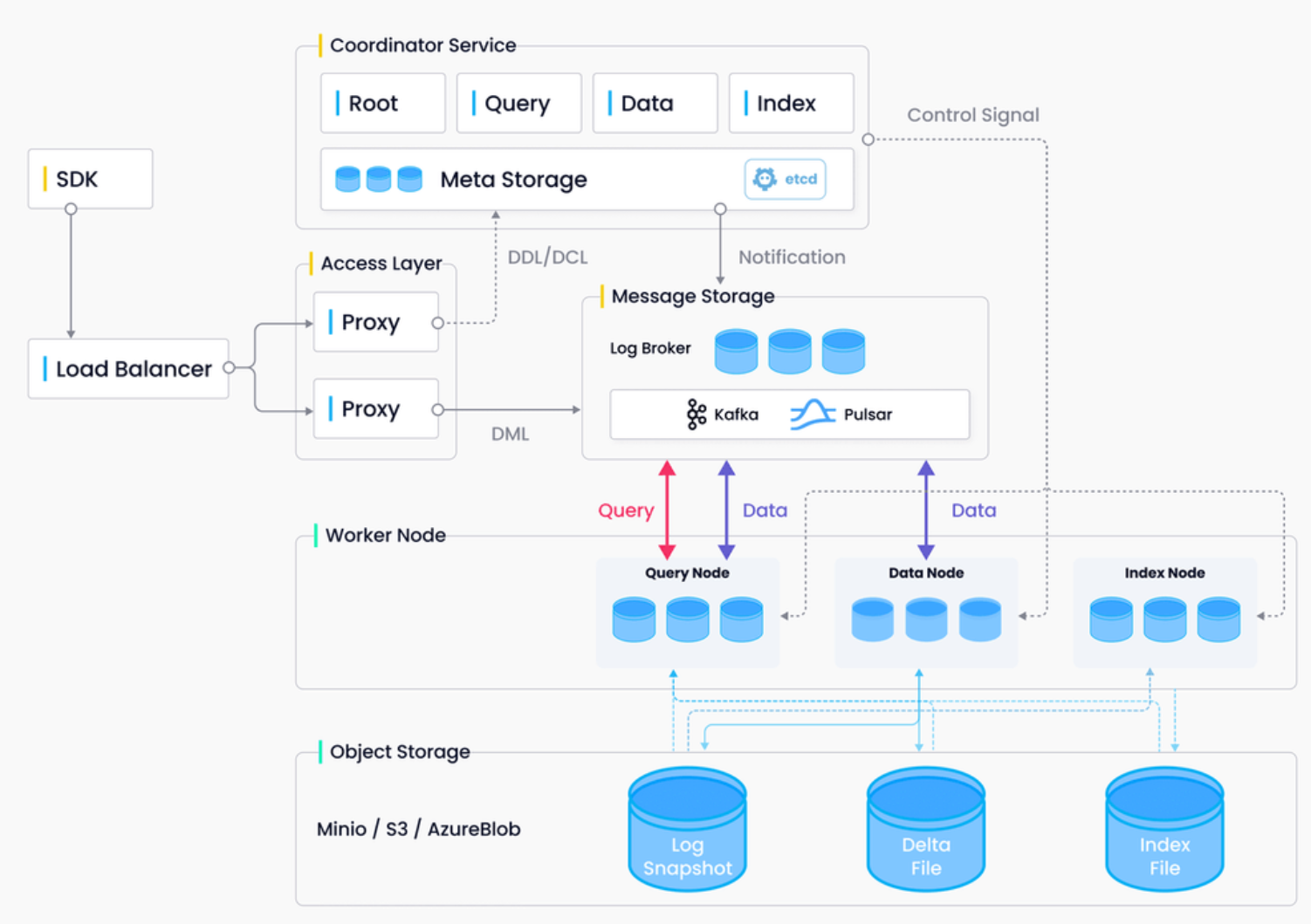
访问层(Access Layer):由一组无状态代理组成,访问层是系统的前端层,也是用户的终端,负责验证客户端请求并合并返回结果。
协调服务(Coordinator Service):协调服务负责分配任务给工作节点,并作为系统的大脑。它承担的任务包括集群拓扑管理、负载均衡、时间戳生成、数据声明和数据管理。
执行节点(Worker Node):负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。
存储服务(Storage):负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
优势特色
-
日志即数据
Milvus 中并没有维护物理上的表,而是通过日志持久化和日志快照来保证数据的可靠性。日志系统作为系统的主干,承担了增量数据持久化和解耦的作用。通过日志的发布-订阅机制,将系统的读、写组件解耦4。
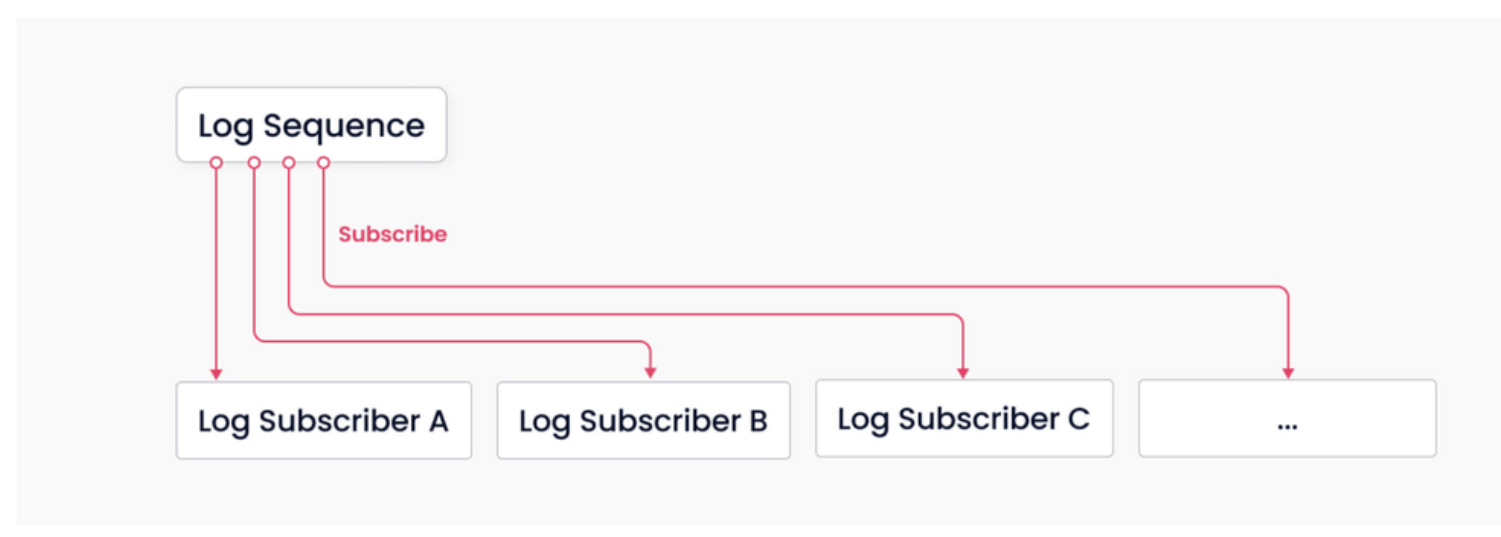
上图中有 Log Sequence 和 Log Subscriber 两种角色:
- Log Sequence: 记录所有改变库表状态的操作
- Log Subscriber: 通过订阅日志序列更新本地数据,以只读副本的方式提供服务
-
流批一体化
首先介绍两个概念:
- 流任务:增量地读取、流式地处理
- 批任务:全量地读取、批式地处理
流批一体化指给定确定的数据源,编写一套代码,执行引擎能够根据需要将代码转换为流任务或批任务,并输出相同的结果。
如上一点所说,Milvus 通过日志更新数据,再将数据批量转换成日志快照,通过对日志快照构建向量索引实现更高的查询效率。查询时,通过合并增量数据和历史数据的查询结果,保证用户可以获取完整的数据视图。这种设计较好地满足了实时性和效率的平衡,降低了传统 Lambda 架构下用户维护离/在线两套系统的负担4。
-
磁盘索引
除了传统的 CAP 的理论之外,还有另一个 CAP 的 Tradeoff ,就是 Cost、Accuracy 和 Performance2。
基于 DiskANN 的磁盘索引可以在仅使用 1/10 的内存消耗下,发挥出 HNSW 索引 1/3-1/2 的性能能力,能够在千万级别的数据上达到 ~10ms 的延迟能力。因此,它可以帮助用户在 QPS、Latency 不特别敏感的场景下大大降低资源的消耗6。
-
更好的性能
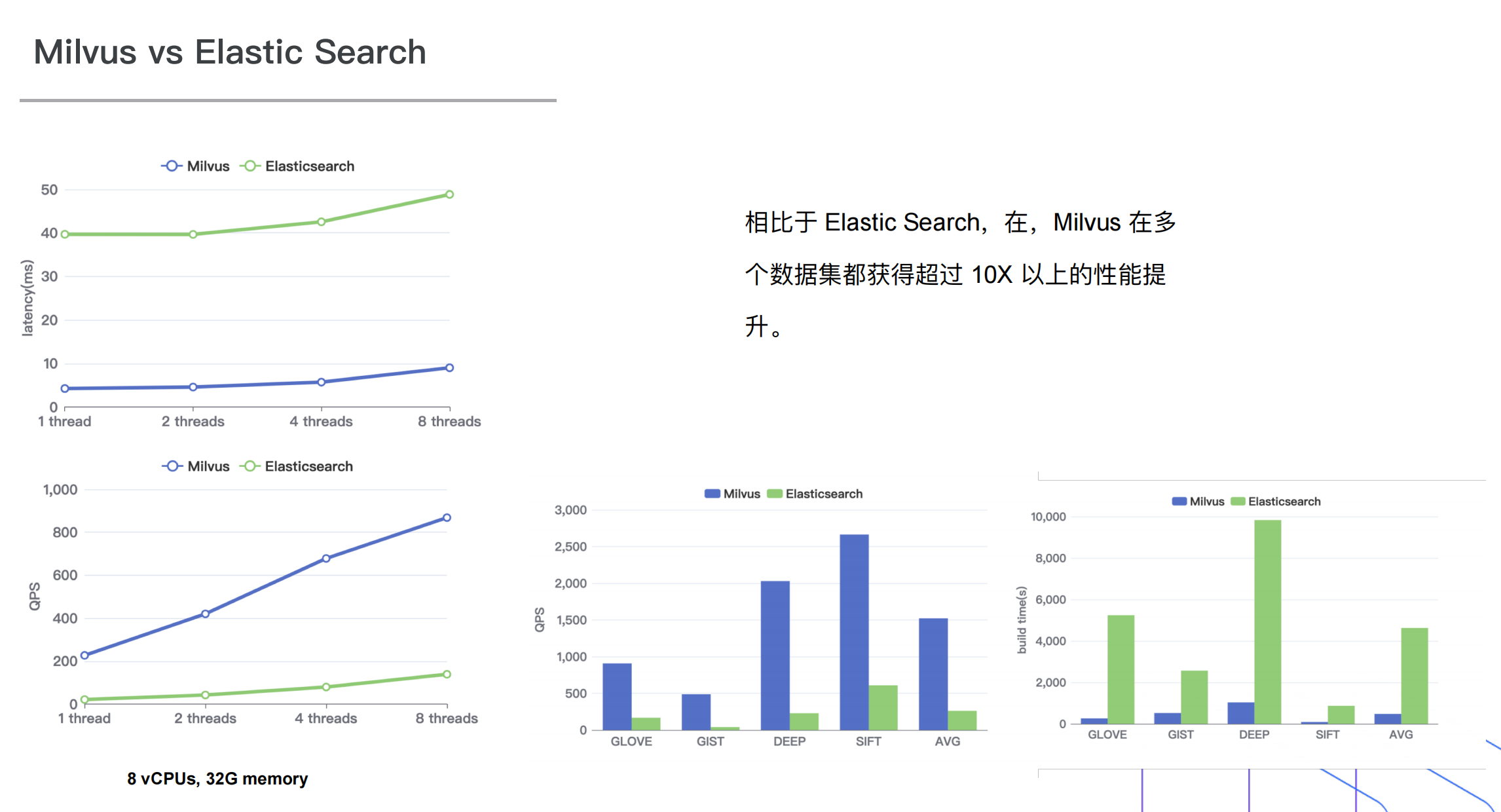
- 开源,支持多种语言开发,目前官方已经有 Python、Java、Go、Node 等主流开发语言的 SDK。
工程实践8
-
创建新环境并下载依赖
conda create -n milvus_movie python=3.9 conda activate milvus_movie pip install ipykernel pymilvus pandas sentence_transformers kaggle -
创建 Zilliz Cloud 集群
注册登录zilliz
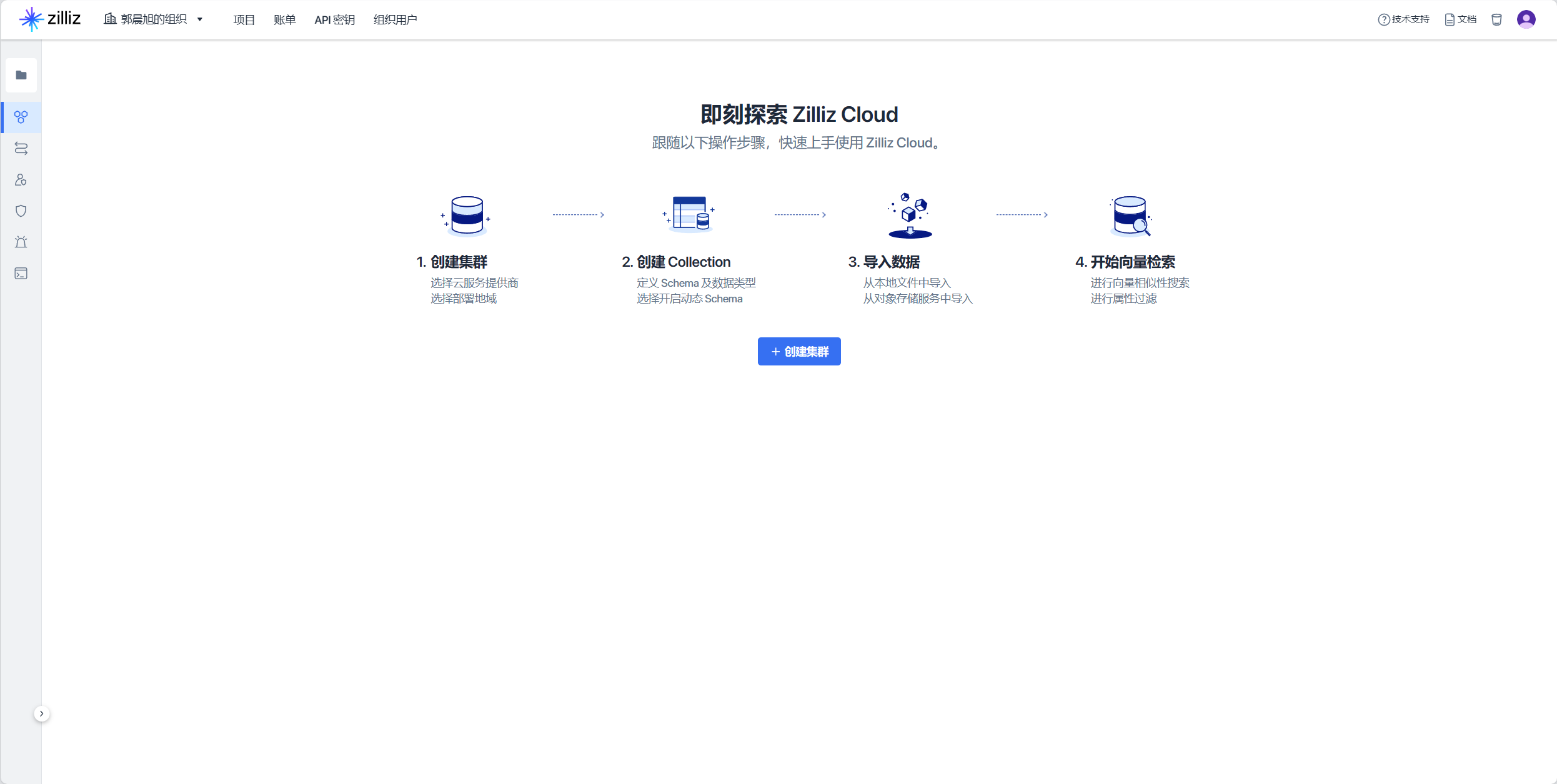
创建集群, 这里我选择腾讯云(因为便宜一点/(ㄒ o ㄒ)/~~)(写后更新,实测整套流程下来需要一个小时左右,最终消费 1.13 元)
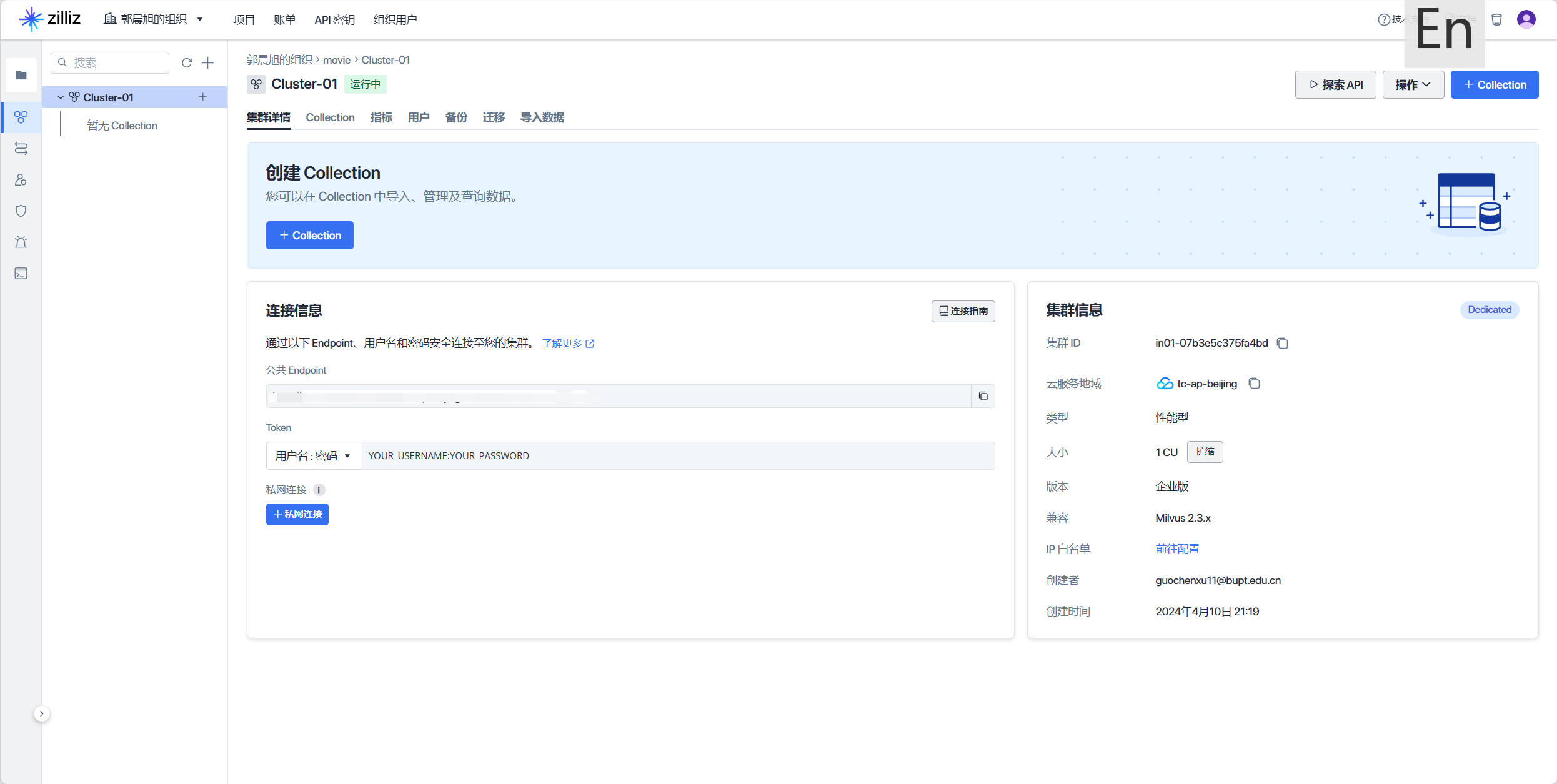
-
在 kaggle 上下载电影数据集 ,我这里是直接浏览器下载本地解压
-
数据预处理
import pandas as pd # 读取数据 movies = pd.read_csv('dataset/movies_metadata.csv',low_memory=False) # 筛选需要的数据 trimmed_movies = movies[["id", "title", "overview", "release_date", "genres"]] print(trimmed_movies.head(5)) # 删除缺少的字段 unclean_movies_dict = trimmed_movies.to_dict('records') print('{} movies'.format(len(unclean_movies_dict))) movies_dict = [] for movie in unclean_movies_dict: if movie["overview"] == movie["overview"] \ and movie["release_date"] == movie["release_date"] \ and movie["genres"] == movie["genres"] \ and movie["title"] == movie["title"]: movies_dict.append(movie)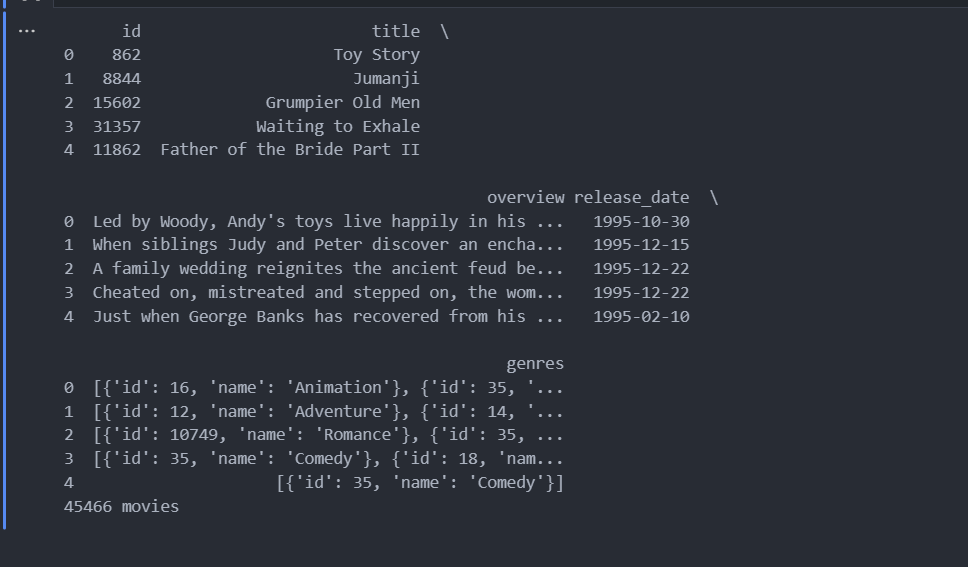
-
连接 Milvus
from pymilvus import * milvus_uri="endpoint" token="token" connections.connect("default", uri=milvus_uri, token=token) print("Connected!")
-
创建 collection 并设置 index
COLLECTION_NAME = 'film_vectors' PARTITION_NAME = 'Movie' """ "title": Film title, "overview": description, "release_date": film release date, "genres": film generes, "embedding": embedding """ id = FieldSchema(name='title', dtype=DataType.VARCHAR, max_length=500, is_primary=True) field = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=384) schema = CollectionSchema(fields=[id, field], description="movie recommender: film vectors", enable_dynamic_field=True) if utility.has_collection(COLLECTION_NAME): collection = Collection(COLLECTION_NAME) collection.drop() collection = Collection(name=COLLECTION_NAME, schema=schema) print("Collection created.") index_params = {"index_type": "IVF_FLAT", "metric_type": "L2", "params": {"nlist": 128},} collection.create_index(field_name="embedding", index_params=index_params) collection.load() print("Collection indexed!")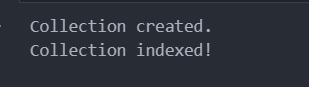
-
生成向量
from sentence_transformers import SentenceTransformer import ast def build_genres(data): genres = data['genres'] genre_list = "" entries= ast.literal_eval(genres) genres = "" for entry in entries: genre_list = genre_list + entry["name"] + ", " genres += genre_list genres = "".join(genres.rsplit(",", 1)) return genres transformer = SentenceTransformer('all-MiniLM-L6-v2') def embed_movie(data): embed = "{} Released on {}. Genres are {}.".format(data["overview"], data["release_date"], build_genres(data)) embeddings = transformer.encode(embed) return embeddings这里需要去 huggingface 上下载
all-MiniLM-L6-v2模型,也可以从镜像 直接打包下载。 -
将向量导入 Milvus
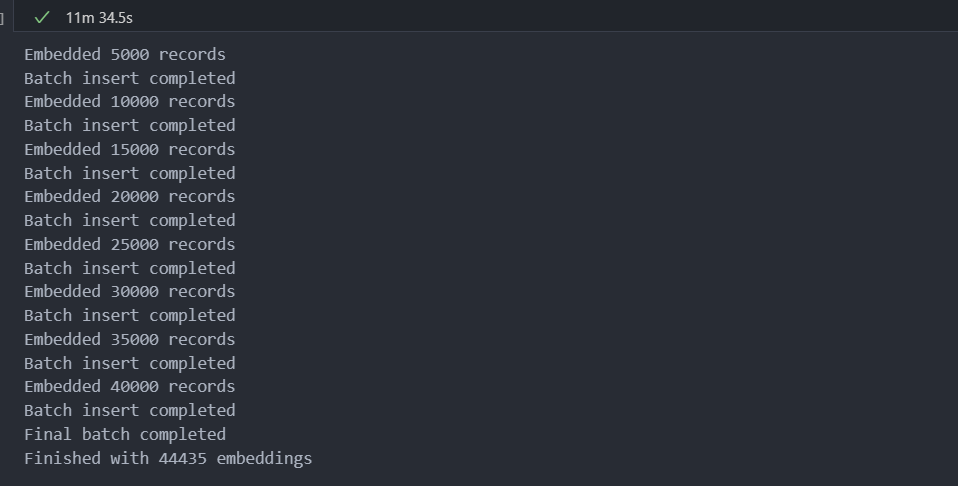
j = 0 batch = [] for movie_dict in movies_dict: try: movie_dict["embedding"] = embed_movie(movie_dict) batch.append(movie_dict) j += 1 if j % 5000 == 0: print("Embedded {} records".format(j)) collection.insert(batch) print("Batch insert completed") batch=[] except Exception as e: print("Error inserting record {}".format(e)) print(batch) break collection.insert(movie_dict) print("Final batch completed") print("Finished with {} embeddings".format(j))为了避免网络消耗,这里我每 5000 条数据插入一次。
-
搜索和推荐电影
collection.load() """ Top-K:topK = 5,规定了搜索将返回 5 个最相似的向量 相似度类型:metric_type 设置为欧氏距离(Euclidean/L2) nprobe:设置为 20,规定了搜索 20 个数据聚类 """ topK = 5 SEARCH_PARAM = { "metric_type":"L2", "params":{"nprobe": 20}, } def embed_search(search_string): search_embeddings = transformer.encode(search_string) return search_embeddings def search_for_movies(search_string): user_vector = embed_search(search_string) return collection.search([user_vector],"embedding",param=SEARCH_PARAM, limit=topK, expr=None, output_fields=['title', 'overview', 'release_date', 'genres']) search_string = "A compelling story of enduring love and resilience" results = search_for_movies(search_string) for hit in results[0]: print('title: ', hit.entity.get('title')) print('overview: ', hit.entity.get('overview')) print('release_date: ', hit.entity.get('release_date')) print('genres: ', hit.entity.get('genres')) print("-------------------------------")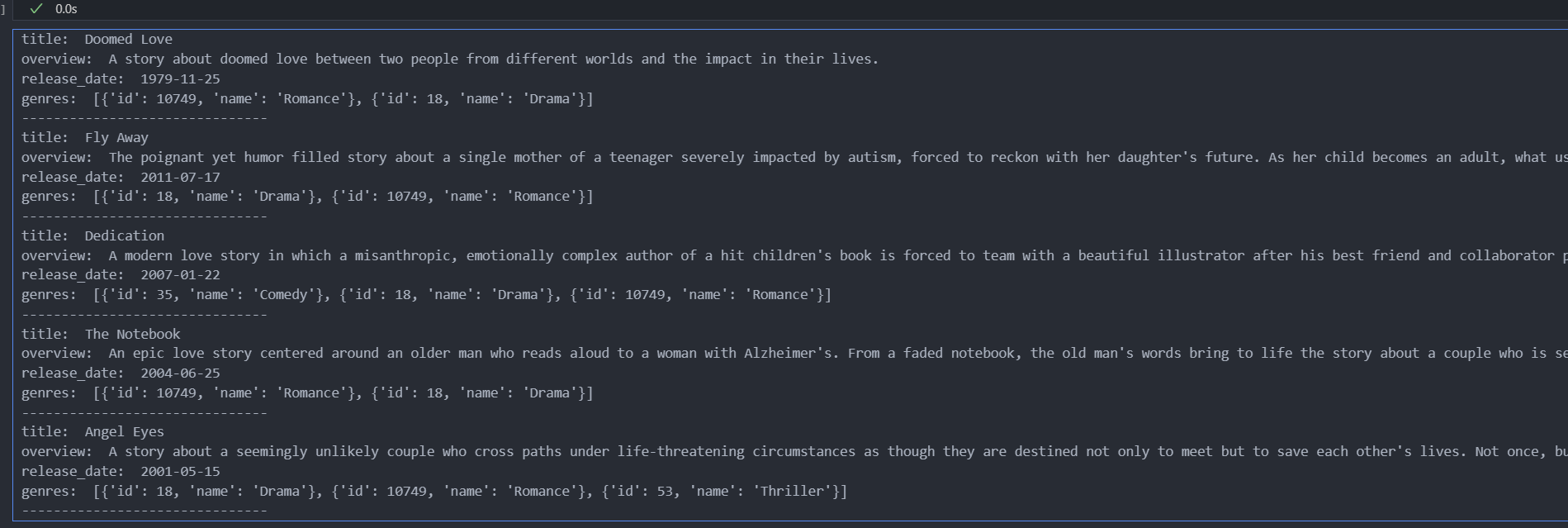
思考
-
系统的易用性
目前向量数据库的查询语言尚未统一,每个向量数据库的都有自定义的查询语法,并且语法规则比较复杂,初学时不好上手。虽然在上层使用时都是使用 sdk 已经封装好的接口,简化了一些操作,但是与传统的 SQL 相比还是较为复杂,这方面希望可以简化或者趋向于“SQL 化”。
这两天看见了好像有类似的东西:PostgreSQL 可以使用 pgvector 向量检索插件进行向量查询, MyScale AI 数据库可以直接用 SQL 查询,下面是 MyScaleDB 的介绍:
MyScale AI 数据库(MyScaleDB)基于高性能的 SQL 列式存储数据库打造,自研高性能和高数据密度的向量索引算法,并针对 SQL 和向量的联合查询对检索和存储引擎进行了深度的研发和优化,是全球第一个综合性能和性价比大幅超越了专用向量数据库的 SQL 向量数据库产品9。
-
分布式与并行计算能力
多个节点并行计算,缩短计算时间。设计分布式系统考虑容灾备份、负载均衡、数据分片等因素。
-
性能提升和成本考虑
像前文提到的新的 CAP(Cost, Accuray, Performance)权衡,保证高效的搜索算法,同时也要考虑成本的增加。
