配置文件
core-site.xml
<!-- 主节点 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node4:8020</value>
</property>
<!-- obs桶的配置 -->
<property>
<name>fs.obs.access.key</name>
<value>***</value>
</property>
<property>
<name>fs.obs.secret.key</name>
<value>***</value>
</property>
<property>
<name>fs.obs.endpoint</name>
<value>obs.cn-north-4.myhuaweicloud.com</value>
</property>
hdfs-site.xml
<!-- secondaryNamenode配置 -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node4:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node4:50091</value>
</property>
</configuration>
yarn-site.xml
<!-- resourcemanger 配置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node4</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node4:19888/jobhistory/logs</value>
</property>
mapred-site.xml
<!-- mapreduce配置 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node4:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node4:19888</value>
</property>
slaves (从节点配置)
node1
node2
node3
其他 hosts 或者免密登录等配置文件省略
启动
主节点输入hadoop namenode -format格式化, 然后输入 start-all.sh 启动 hadoop, 使用 JPS 查看当前 java 进程, 根据上述配置应该有如下显示
主节点:

从节点:
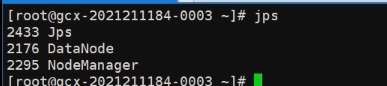
各进程含义:
- NameNode: 存储数据元信息
- SecondaryNameNode: 合并 NameNode 的
edit logs和fsimage文件, 帮助恢复 NameNode - ResourceManager: 资源的管理和调度
- DataNode: 数据信息
- NodeManger: 接收 ResourceManager 的资源调度
增删改查
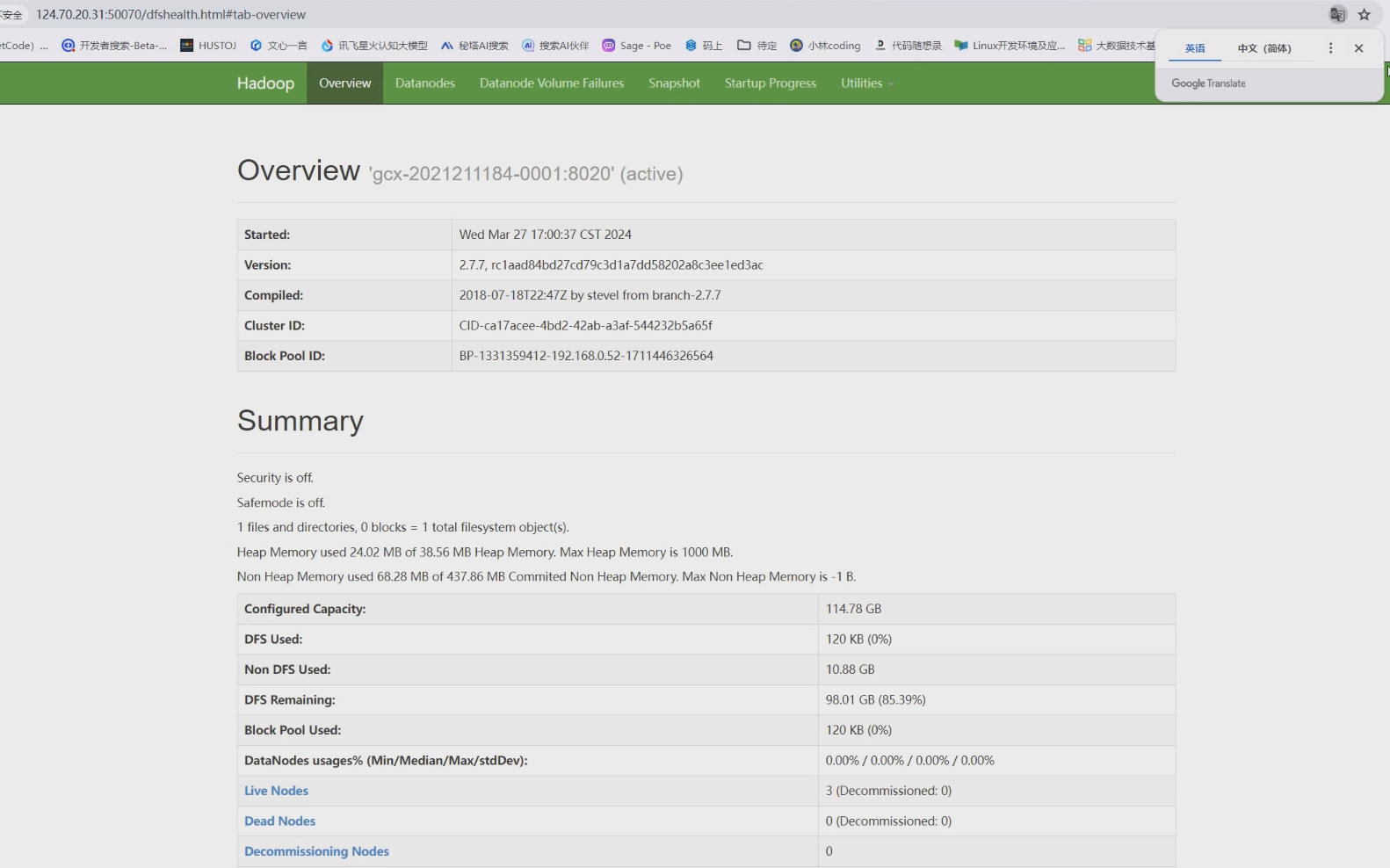
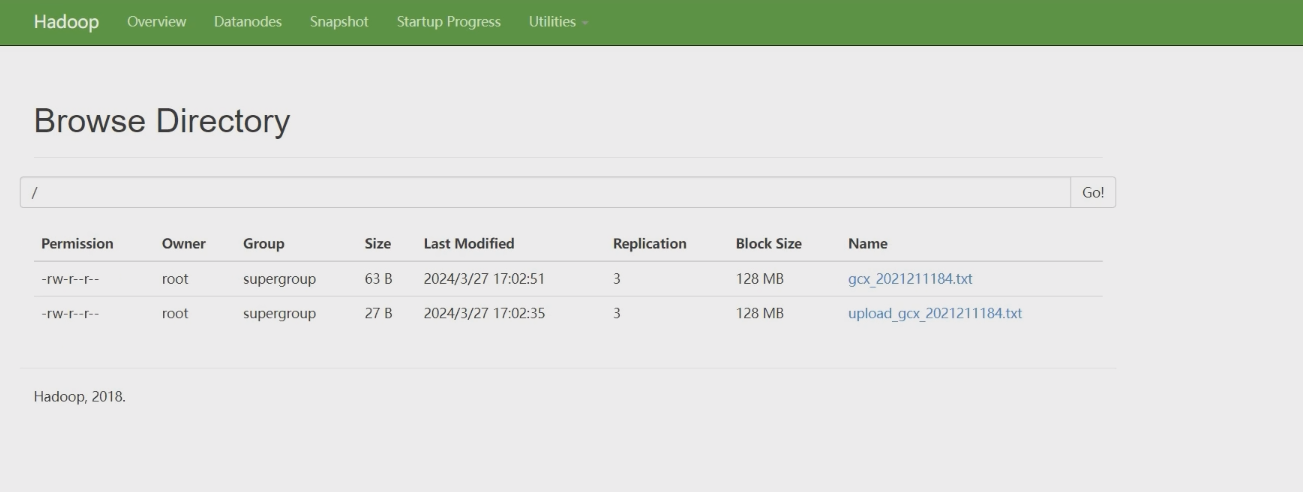
浏览器访问主节点 50070 端口, 查看 hadoop 网页页面
先声明路径
String hdfsPath = "/";
主函数调用如下, 调用流程: 查看 -> 上传 -> 创建 -> 下载 -> 查看 -> 删除 -> 查看
public static void main(String[] args) {
ExeHDFS testHDFS = new ExeHDFS();
try {
testHDFS.testView();
testHDFS.testUpload();
testHDFS.testCreate();
testHDFS.testDownload();
testHDFS.testView();
testHDFS.testDelete();
testHDFS.testView();
} catch (Exception e) {
e.printStackTrace();
}
}
查看的代码:
// 查看HDFS文件系统
public void testView() throws IOException, URISyntaxException, InterruptedException {
System.out.println("View file:");
Configuration conf = new Configuration();
conf.set("dfs.client.use.datanode.hostname", "true");
conf.set("fs.defaultFS", "hdfs://124.70.20.31:8020");
FileSystem hdfs = FileSystem.get(new URI("hdfs://124.70.20.31"), conf, "root");
Path path = new Path(hdfsPath);
FileStatus[] list = hdfs.listStatus(path);
if (list.length == 0) {
System.out.println("HDFS is empty.");
} else {
for (FileStatus f : list) {
System.out.printf("name: %s, folder: %s, size: %s\n", f.getPath(), f.isDirectory(), f.getLen());
}
}
hdfs.close();
}
上传的代码:
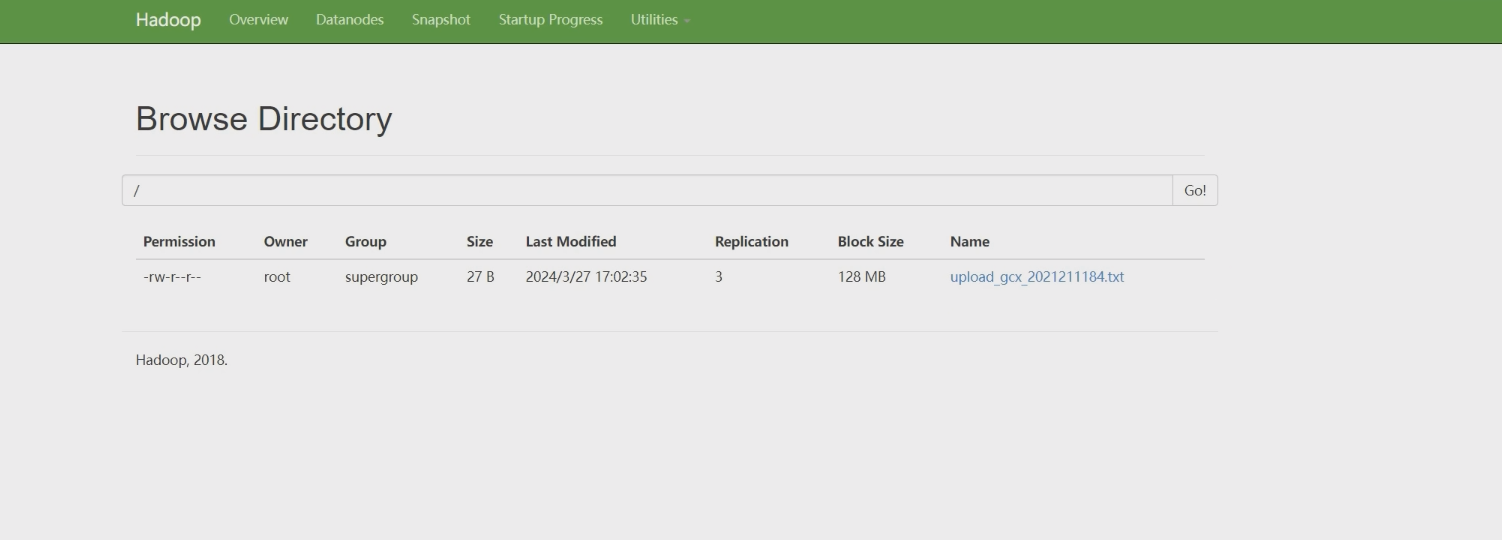
// 上传本地文件到HDFS
public void testUpload() throws IOException, URISyntaxException, InterruptedException {
System.out.println("Upload file:");
Configuration conf = new Configuration();
conf.set("dfs.client.use.datanode.hostname", "true");
conf.set("fs.defaultFS", "hdfs://124.70.20.31:8020");
FileSystem hdfs = FileSystem.get(new URI("hdfs://124.70.20.31"), conf, "root");
InputStream in = Files.newInputStream(Paths.get("./exp1/src/main/resources/upload.txt"));
OutputStream out = hdfs.create(new Path(hdfsPath + "upload_gcx_2021211184.txt"));
IOUtils.copyBytes(in, out, conf);
System.out.println("Upload successfully!");
hdfs.close();
in.close();
out.close();
}
创建的代码:
// 创建HDFS文件
public void testCreate() throws Exception {
System.out.println("Write file:");
Configuration conf = new Configuration();
conf.set("dfs.client.use.datanode.hostname", "true");
conf.set("fs.defaultFS", "hdfs://124.70.20.31:8020");
// 待写入文件内容
// 写入自己姓名与学号
byte[] buff = "Hello world! My name is 郭晨旭, my student id is 2021211184.".getBytes();
// FileSystem 为 HDFS 的 API, 通过此调用 HDFS
FileSystem hdfs = FileSystem.get(new URI("hdfs://124.70.20.31"), conf, "root");
// 文件目标路径,应填写 hdfs 文件路径
Path dst = new Path(hdfsPath + "gcx_2021211184.txt");
try (FSDataOutputStream outputStream = hdfs.create(dst)) {
// 写入文件
outputStream.write(buff, 0, buff.length);
} catch (Exception e) {
e.printStackTrace();
}
// 检查文件写入情况
FileStatus[] files = hdfs.listStatus(dst);
for (FileStatus file : files) {
// 打印写入文件路径及名称
System.out.println(file.getPath());
}
hdfs.close();
}
下载的代码:
// 从HDFS下载文件到本地
public void testDownload() throws IOException, URISyntaxException, InterruptedException {
System.out.println("Download file:");
Configuration conf = new Configuration();
conf.set("dfs.client.use.datanode.hostname", "true");
conf.set("fs.defaultFS", "hdfs://124.70.20.31:8020");
FileSystem hdfs = FileSystem.get(new URI("hdfs://124.70.20.31"), conf, "root");
InputStream in = hdfs.open(new Path(hdfsPath + "gcx_2021211184.txt"));
OutputStream out = Files.newOutputStream(Paths.get("./exp1/src/main/resources/download_gcx_2021211184.txt"));
IOUtils.copyBytes(in, out, conf);
System.out.println("Download successfully!");
hdfs.close();
in.close();
out.close();
}

删除的代码:
// 从hdfs删除文件
public void testDelete() throws URISyntaxException, IOException, InterruptedException {
System.out.println("Delete file:");
Configuration conf = new Configuration();
conf.set("dfs.client.use.datanode.hostname", "true");
conf.set("fs.defaultFS", "hdfs://124.70.20.31:8020");
FileSystem hdfs = FileSystem.get(new URI("hdfs://124.70.20.31"), conf, "root");
System.out.println(hdfsPath + "gcx_2021211184.txt");
boolean delete = hdfs.delete(new Path(hdfsPath + "gcx_2021211184.txt"), true);
if (delete) {
System.out.println("Delete successfully!");
} else {
System.out.println("Delete failed!");
}
System.out.println(hdfsPath + "upload_gcx_2021211184.txt");
delete = hdfs.delete(new Path(hdfsPath + "upload_gcx_2021211184.txt"), true);
if (delete) {
System.out.println("Delete successfully!");
} else {
System.out.println("Delete failed!");
}
hdfs.close();
}
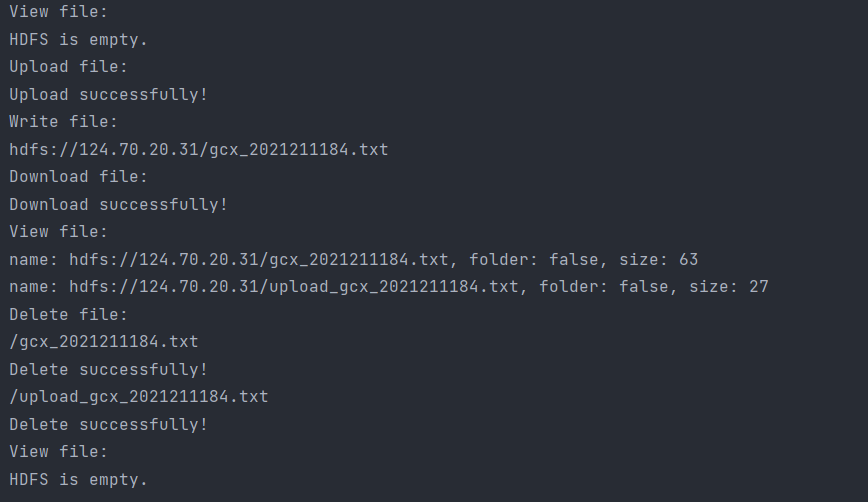
整体流程的控制台输出效果:
实验中遇到的 bug
-
jdk 的解压问题
提供的 8u292b10 版 jdk 的压缩包需要在 linux 环境下解压,如果在 windows 下解压然后 scp 到服务器上,会丢失部分设置信息导致后期运行
start-all.sh会丢失NodeManager等进程 -
云防火墙问题
需要去华为的云防火墙打开 50091 端口,让
datanode可以被外部 PC 机访问 -
hadoop namenode -format问题如果运行
hadoop namenode -format后出现问题,打算第二次运行本条指令,需要删除 tmp 文件夹下所有 dfs 文件,否则会丢失datanode进程 -
hosts 编辑问题
/etc/hosts需要注释掉本地环回 ip,否则datanode只能被 127.0.0.1 访问到
课程内容复习
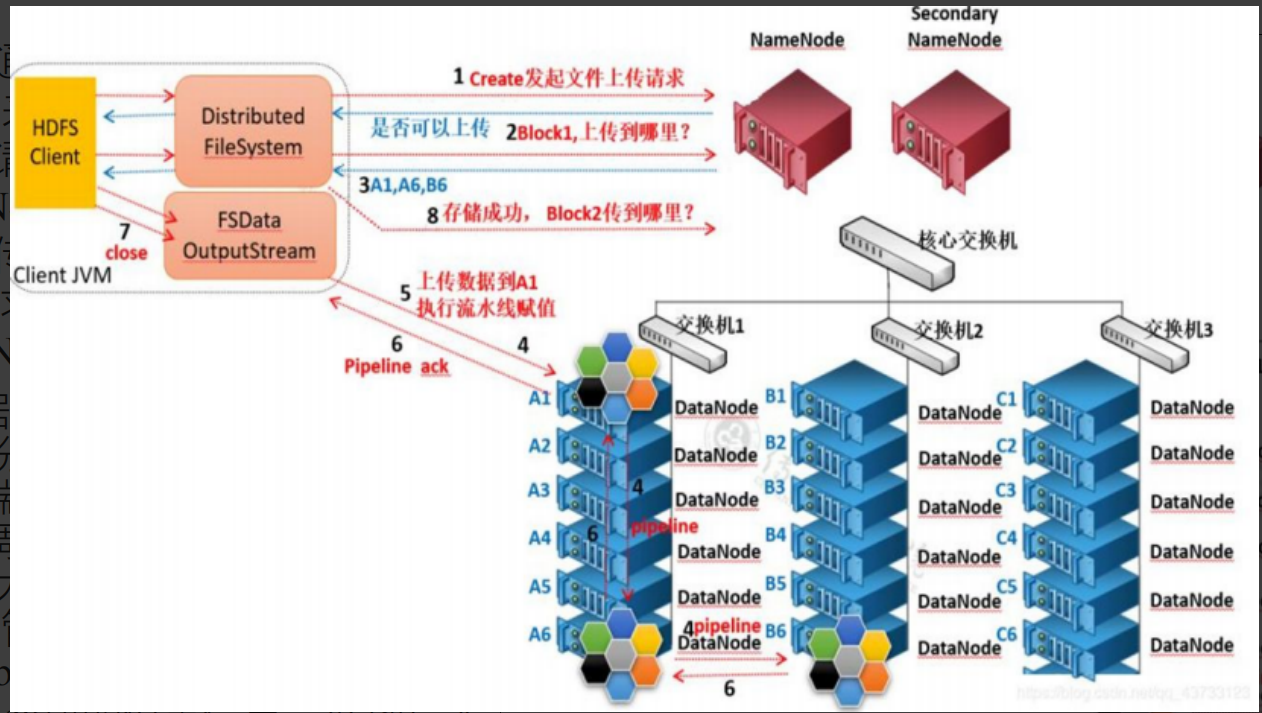
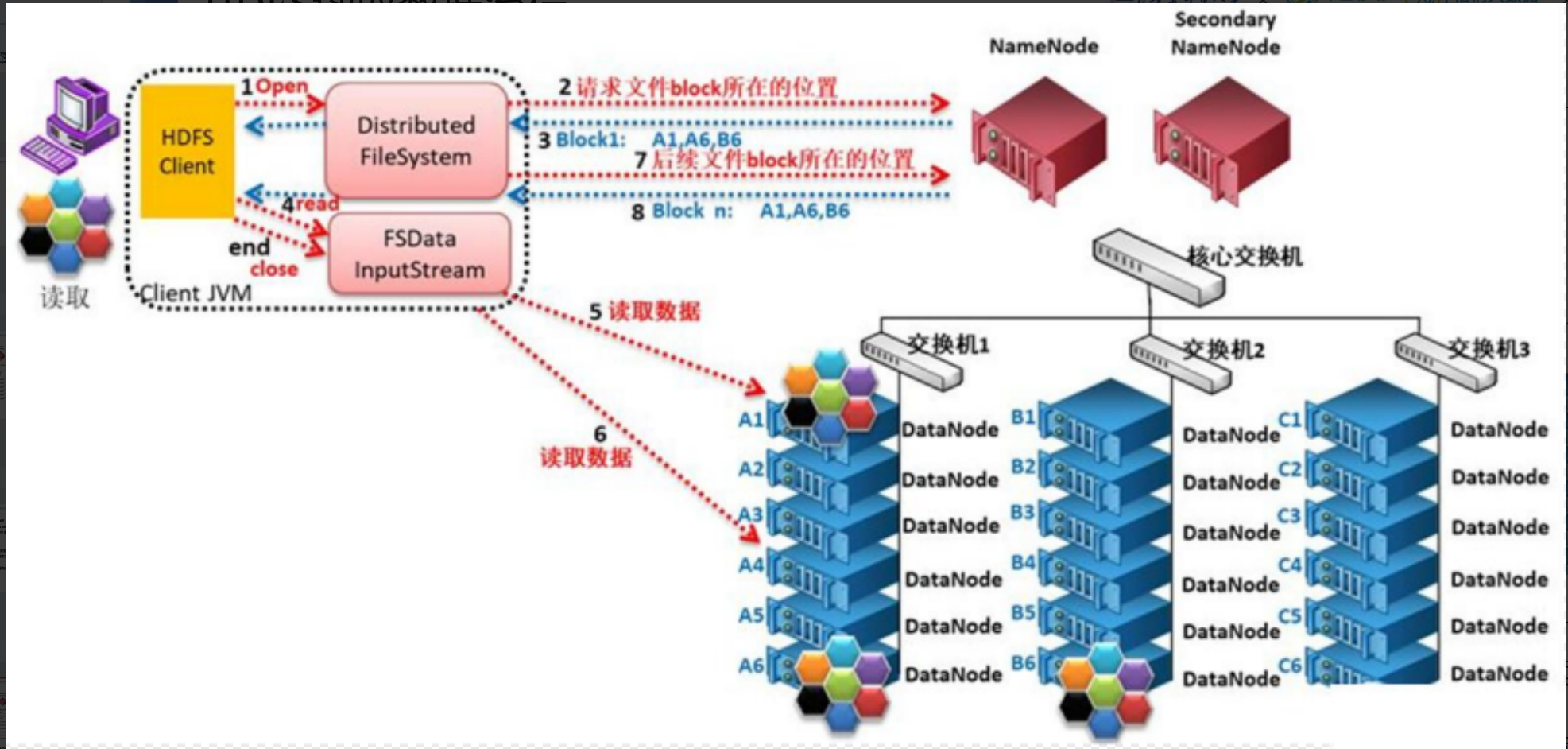
HDFS 的写入和读取
HDFS 的写入:
HDFS 的读取:
容错机制
由上述内容分析可得, 常见的出错情况有 NameNode 节点出错、DataNode 节点出错 和 数据出错 这三种情况.
NameNode 节点出错
HDFS 中所有元数据都保存在 NameNode 上, NameNode 节点维护 edits 和 fsimage 这两个文件, Hadoop 中提供了两个机制,来确保 NameNode 的安全:
- 运行一个 SecondaryNameNode 节点, 当 NameNode 宕机时, 利用 SecondaryNameNode 保存的 checkpoint 进行系统恢复.
- 把 NameNode 节点上的元数据信息同步存储到其他文件系统 (比如 NFS ), 当 NameNode 出现故障时, HDFS 自动切换到备用的 NameNode 上;
DataNode 节点出错
每个 DataNode 周期性地向 NameNode 发送心跳信号, NameNode 通过心跳信号来检测 DataNode 是否存活.
数据块需要重新复制的情况:
- 某个 DataNode 节点丢失;
- DataNode 上的硬盘出错;
- 某个副本损坏;
- 某个数据块的副本系数低于设定值.
数据出错
DataNode 获取的数据块, 有可能本身就是损坏的, 此时 HDFS 使用 校验和 来判断数据块是否损坏, 如果损坏则从其他副本中读取数据.
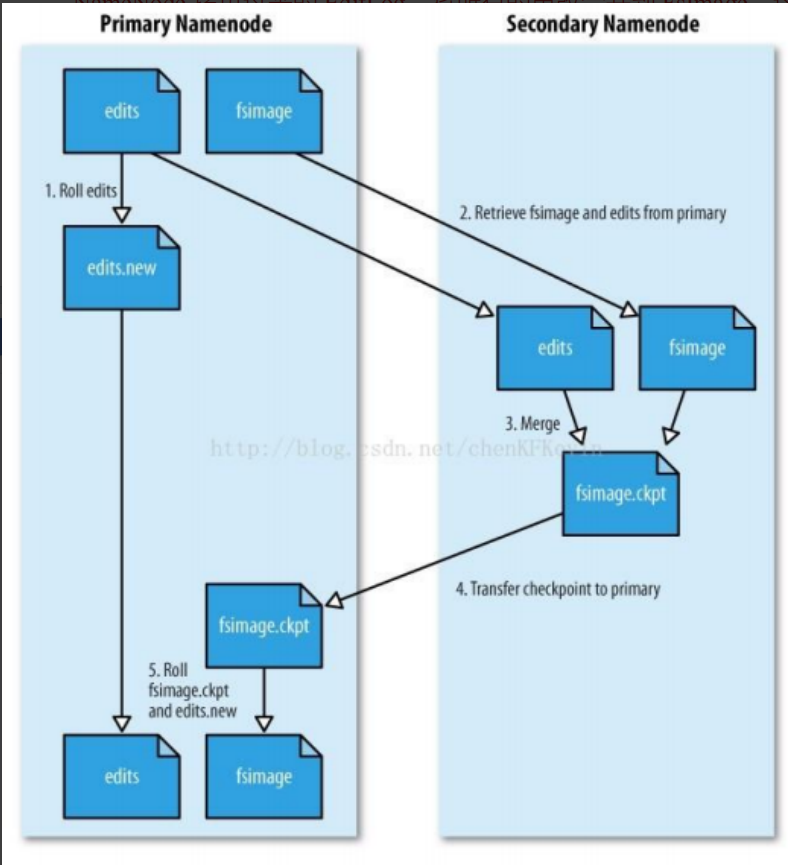
SecondaryNameNode 工作原理
SecondaryNameNode 本质上就是记录 checkpoint, 使 NameNode 下次启动时直接从记录的 checkpoint 开始启动
- edit log: 客户端对 HDFS 所有的更新操作
- fsimage: 某一时刻 HDFS 整体的快照
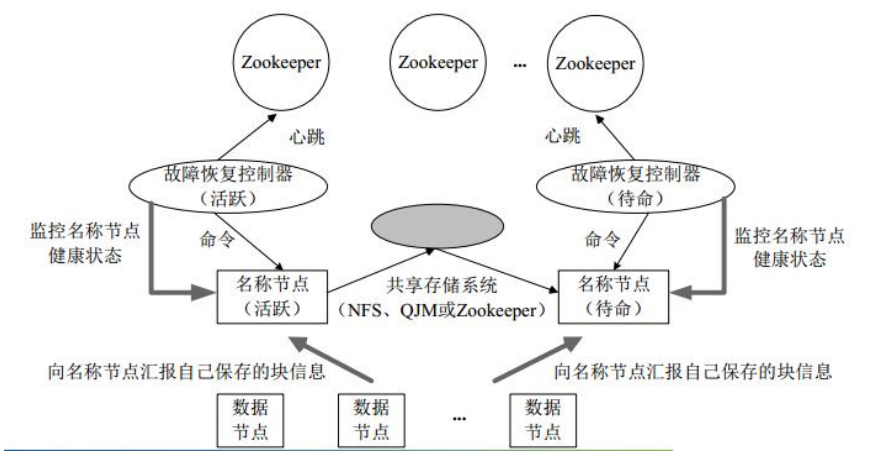
HA 架构
此次实验中我们部署的 HDFS 架构:
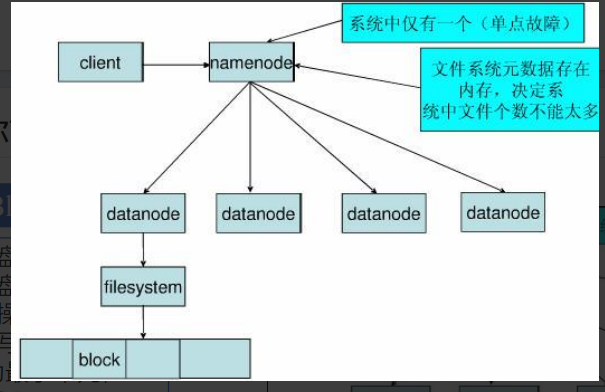
HA 架构, 也就是上述容错机制中的增加一个备用 NameNode, 并使用 FailoverController 检测 NameNode 的活跃状态, 主备架构相同