XGBoost 算法
XGBoost 算法的原理基于梯度提升(Gradient Boosting)框架,其核心思想是构建多个弱预测模型,通常是决策树,并逐步优化以提高整体模型的性能。下面是 XGBoost 的基本流程介绍:
- 初始化模型:开始时,模型可以是一个简单的基模型,如一个常数值,它代表了训练数据的初始预测。
- 计算残差:对于每个训练样本,计算当前模型的预测值与真实值之间的残差(误差)。
- 构建新的弱模型:利用残差作为目标,训练一个新的弱模型(通常是决策树)。这个新模型的目的是预测每个样本的残差。
- 更新模型:将新训练的弱模型以一定的学习率添加到现有模型中,更新整体模型的预测。
- 正则化:在更新过程中,引入正则化项(L1 和 L2 正则化),以防止模型过于复杂,减少过拟合的风险。
- 迭代优化:重复步骤 2 到 5,直到达到预定的迭代次数或模型性能不再显著提升。
XGBoost 特点:
- 梯度提升:XGBoost 使用梯度提升决策树(GBDT)作为基学习器,通过迭代地添加新的树来最小化损失函数。
- 正则化:XGBoost 在损失函数中加入了正则化项,包括 L1(Lasso)和 L2(Ridge)正则化,这有助于防止模型过拟合。
- 灵活性:XGBoost 支持用户自定义的损失函数和评估标准,使其能够灵活地应用于各种机器学习任务。
- 剪枝:XGBoost 在生长树的过程中,会对树进行剪枝,以避免过拟合。
性能评价标准
True/False: 机器判断结果的对/错
Positive/Negative: 机器判断结果的正/负
| True | False | |
|---|---|---|
| Positive | TP | FP |
| Negative | TN | FN |
准确率 – Accuracy
预测正确的结果占总样本的百分比 $$准确率 =(TP+TN)/(TP+TN+FP+FN)$$
精确率(差准率)- Precision
所有被预测为正的样本中实际为正的样本的概率 $$精准率 =TP/(TP+FP)$$
召回率(查全率)- Recall
实际为正的样本中被预测为正样本的概率 $$召回率=TP/(TP+FN)$$
F1-score
为了综合精确率和召回率的表现,在两者之间找一个平衡点,就出现了一个 F1 分数。
$$F1-score = \frac{2 \times Precision \times Recall}{Precision+Recall}$$
ROC 和 AUC
在利用精确率和召回率两个指标时,这两个指标是随着我们设定的分类的阈值变化的,具有一定的主观性,但是我们希望有更好的指标克服这个缺点,能够客观描述一个模型的质量,这就是 ROC 曲线。
$$灵敏度(Sensitivity) = TP/(TP+FN)$$ $$特异度(Specificity) = TN/(FP+TN)$$ $$真正率(TPR) = 灵敏度 = TP/(TP+FN)$$ $$假正率(FPR) = 1- 特异度 = FP/(FP+TN)$$
ROC 曲线以真正率 TPR 为纵轴,以假正率 FPR 为横轴,在不同的阈值下获得坐标点,并连接各个坐标点,得到 ROC 曲线。
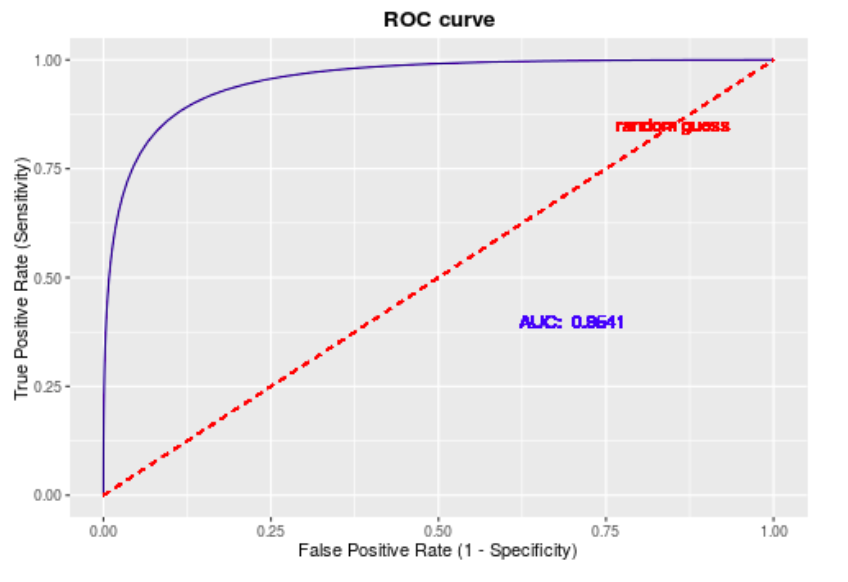
AUC 被定义为 ROC 曲线下的面积,使用 AUC 值作为评价标准是因为很多时候 ROC 曲线并不能清晰的说明哪个分类器的效果更好,分类器对应的 AUC 越大说明其效果越好。
