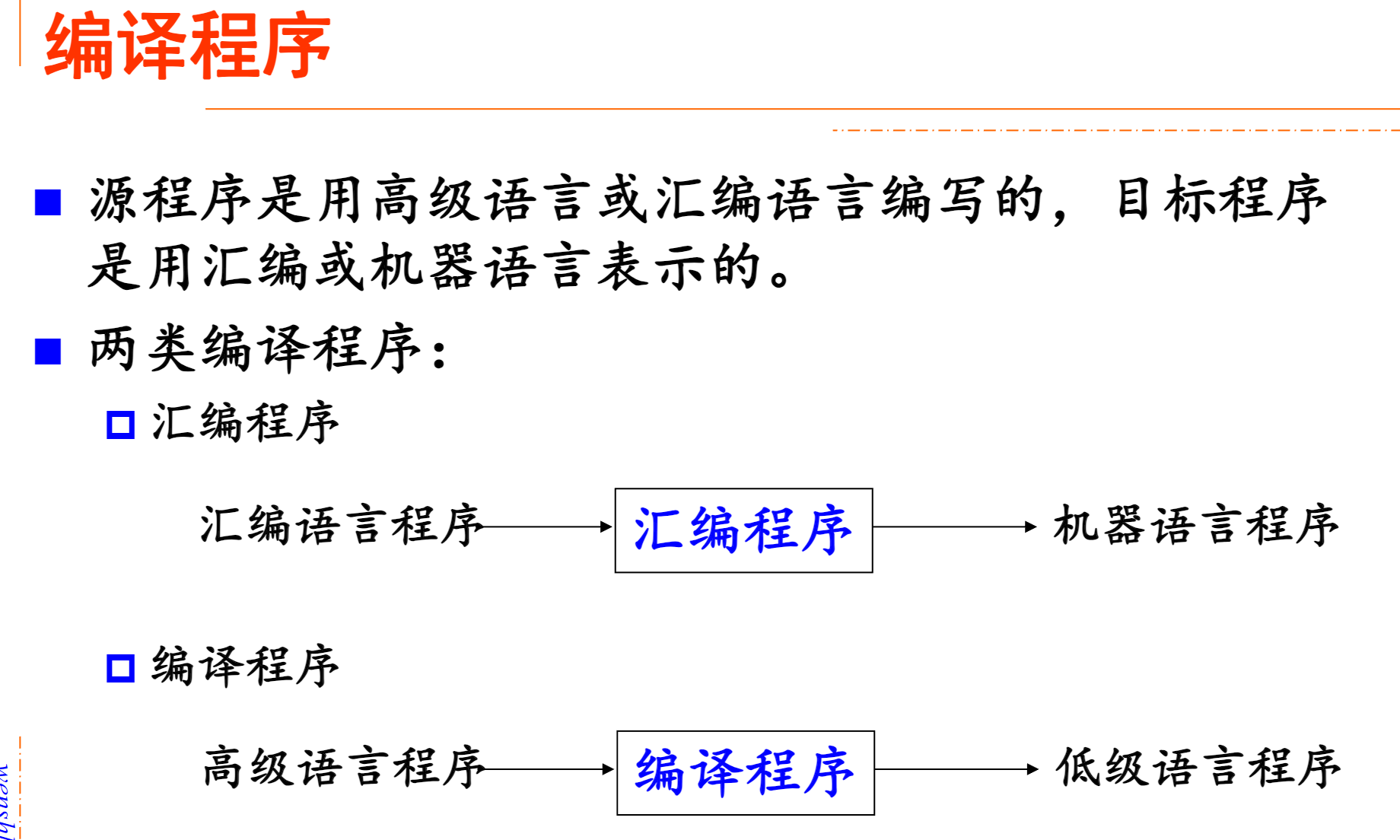
编译概述
翻译和解释

编译的阶段和任务
分析阶段: 根据原语言的定义, 分析源程序 1. 词法分析 2. 语法分析 3. 语义分析
综合阶段: 根据分析结果构造目标程序 4. 中间代码生成 5. 代码优化 6. 目标代码生成
符号表的管理 错误诊断和处理
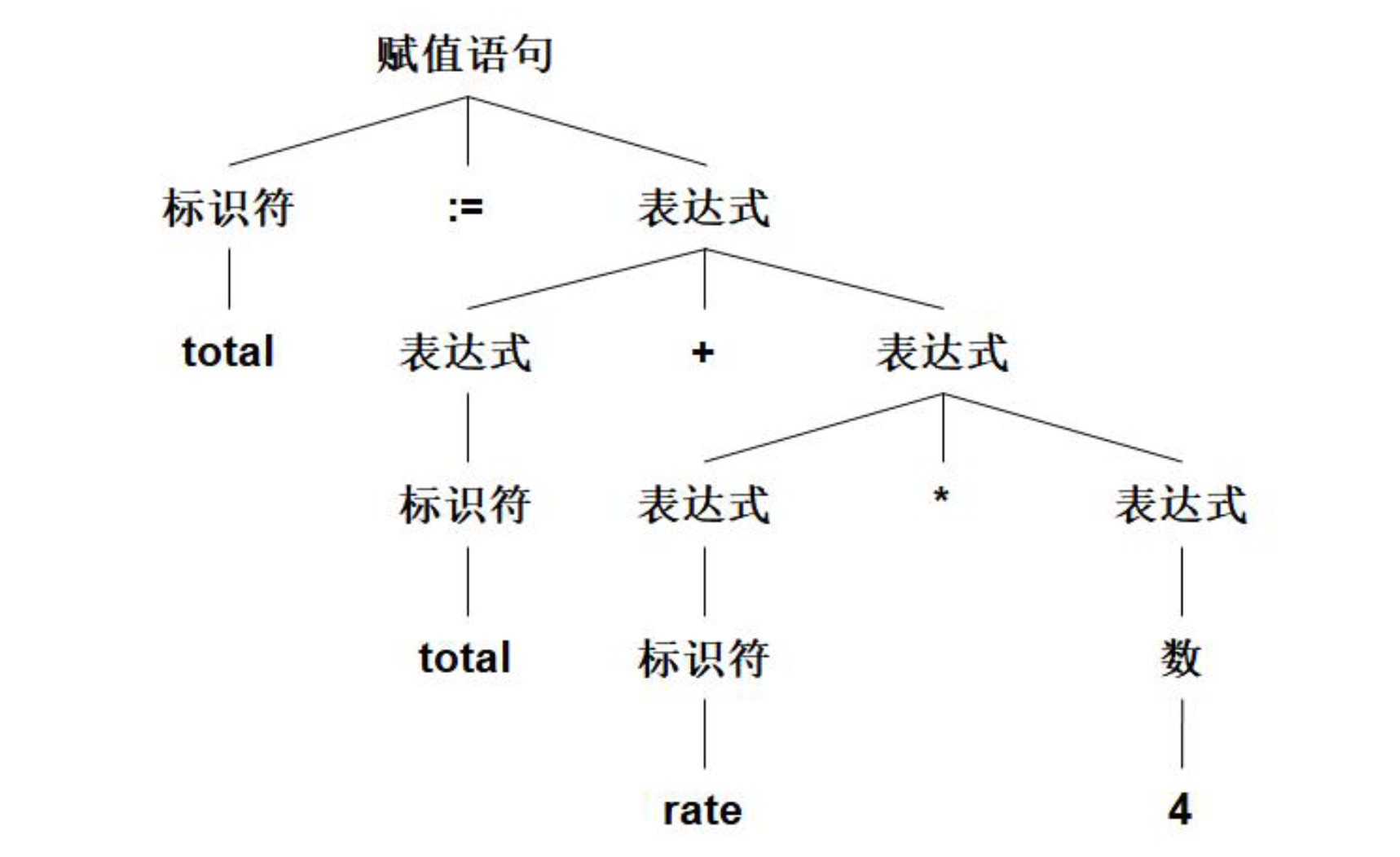
total := total + rate * 4 语法分析的分析树:
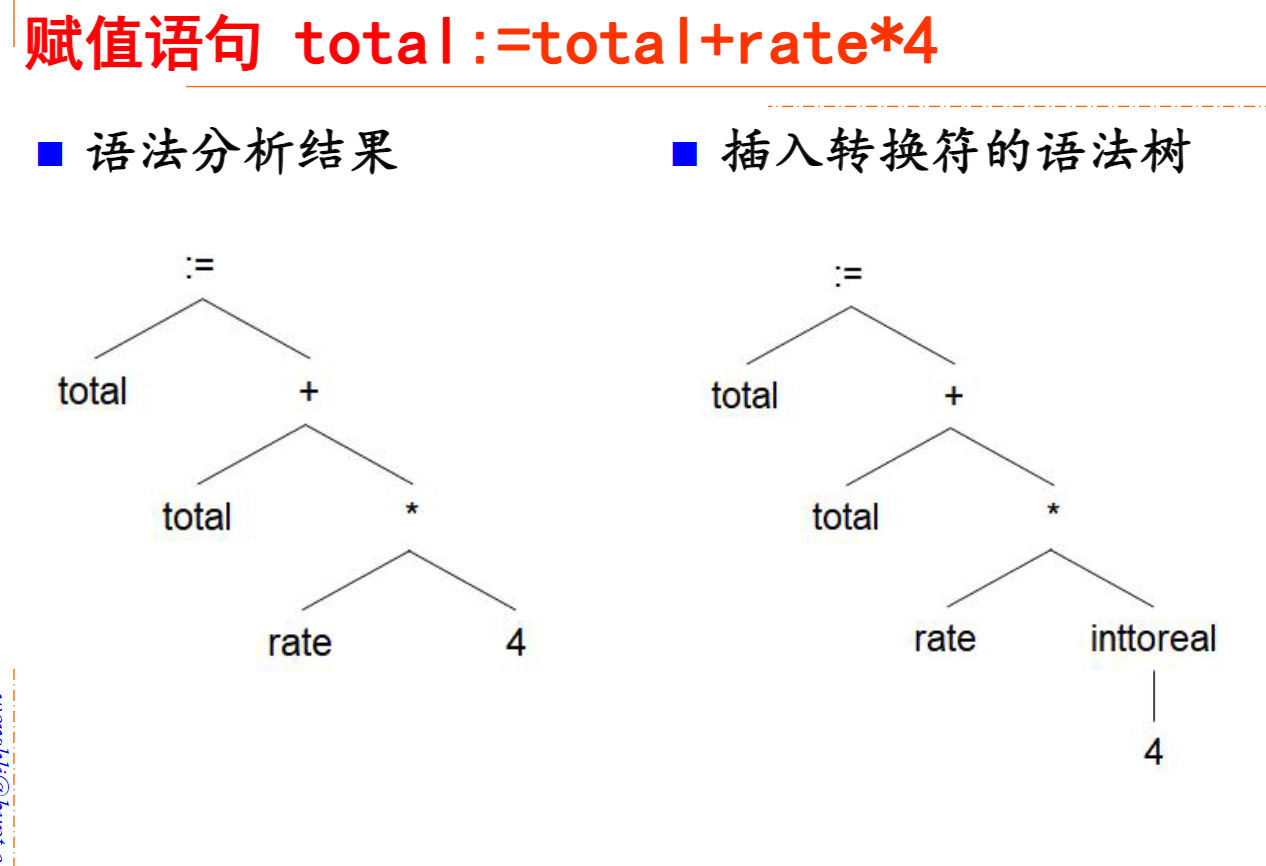
total := total + rate * 4 语义分析的语法树:
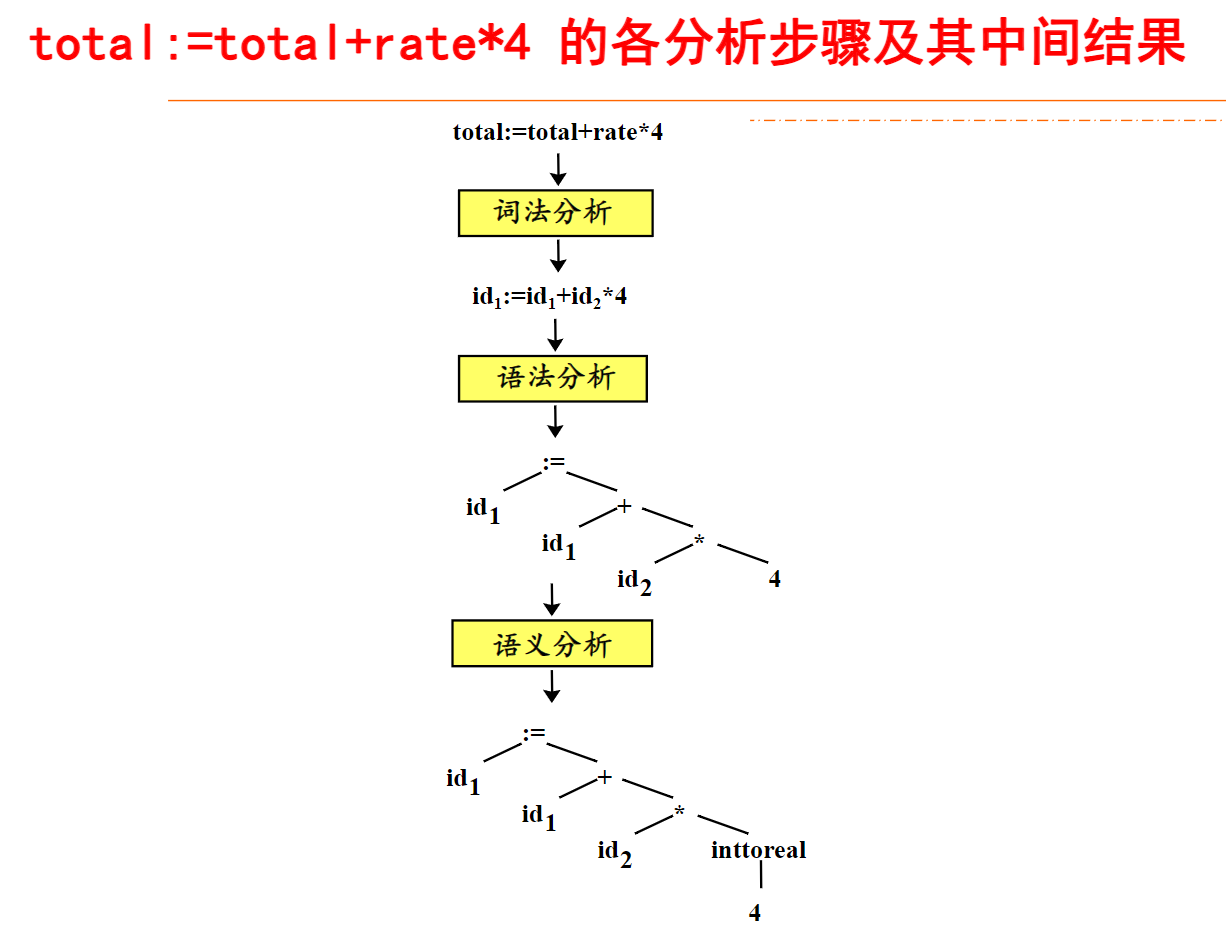
编译有关的其他概念
前端: 与源语言有关而与目标机器无关的部分 词法分析、语法分析、符号表的建立、语义分析和中间代码生成 与机器无关的代码优化工作 相应的错误处理工作和符号表操作
后端: 与目标机器有关的部分 目标代码的生成、与机器有关的代码优化 相应的错误处理和符号表操作
前后端的优点: 便于编译程序的移植和构造
“遍” 的概念: 对源程序或其中间形式从头到尾扫描一遍, 并作相关的加工处理, 生成新的中间形式或目标程序. 分遍的优点: 减少对主存容量的要求; 各遍编译程序功能独立、单纯,相互联系简单,编译程序结构清晰; 更充分的优化工作,获得高质量目标程序; 为编译程序的移植创造条件.
分遍的缺点: 增加了不少重复性的工作.
编译程序的伙伴工具
编译程序的前后处理器:
1. 预处理器
2. 汇编程序
3. 连接装配程序
预处理器
- 宏处理
- 文件包含
- 语言补充
汇编程序
汇编语言用助记符表示操作码, 用标识符表示存储地址.
连接装配程序
编译原理的应用
词法分析
词法分析程序与语法分析程序的关系
词法分析作用: 扫描源程序字符流 按照源语言的词法规则识别出各类单词符号 产生用于语法分析的记号序列 词法检查 与用户接口的一些任务 - 跳过注释和空白 - 把错误和源程序联系起来 创建符号表
词法分析和语法分析关系: 词法分析作为独立的一遍 词法是语法的子程序 词法是语法的协同程序
分离词法分析程序的好处 简化设计 改进编译程序的效率 加强编译程序的可移植性
词法分析程序的输入与输出
设置缓冲区: 为了得到一个单词字符的确切性质, 需要超前扫描若干字符
记号: 某一类单词符号的类别编码
模式: 某一类单词符号的构词规则
单词: 某一类单词符号的一个特例
记号的属性
- 词法分析程序在识别出一个记号后,要把与之有关的信息作为它的属性保留下来。
- 记号影响语法分析的决策,属性影响记号的翻译。
- 在词法分析阶段,对记号只能确定一种属性
- 标识符:单词在符号表中的入口指针
- 常数:它所表示的值
- 关键字:(一符一种、或一类一种)
- 运算符:(一符一种、或一类一种)
- 分界符:(一符一种、或一类一种)
记号的描述和识别
词法:描述语言的标识符、常数、运算符和标点符号等记号的文法
语法:借助于记号来描述语言的结构的文法
文法书写约定:
-
终结符号:
- 次序靠前的小写字母,如:a、b、c
- 运算符号,+、-…
- 各种标点符号
- 数字 1、2、……9
- 黑体字符串 id、if…
-
非终结符号
- 次序靠前的大写字母
- 大写字符 S 常用作文法的开始符号
- 小写的斜体符号串 expr、term…
-
文法符号
- 次序靠后的大写字母
-
终结符号串
- 次序靠后的小写字母
-
文法符号串
- 小写的希腊字母 $\alpha$、$\beta$…
词法分析程序的设计与实现
语法分析
语法分析简介
自顶向下分析
递归下降分析
从上到下,从左到右分析,最左推导,不断试探和回溯
左递归可能会导致死循环,例如: A $\rightarrow$ Ab | b, 如果识别到了 A, 就会一直执行 A $\rightarrow$ Ab
消除左递归:

递归调用预测分析
非递归预测分析
First 集合, 注意空串的条件

对于 $A \rightarrow BC$, 如果只有 $B$ 能够推出 $\varepsilon$ 元素(不一定是一步推出), 则 $B$ 和 $C$ 中的所有非 $\varepsilon$ 元素都要加入到 $First(A)$ 中; 如果 $B$ 和 $C$ 能同时推导出 $\varepsilon$ 元素, 才会有 $\varepsilon \in First(A)$
Follow 集合中一定不会有空串

注意上述规则的第三点, 若有 $A \rightarrow BC$ 且 $C \rightarrow \varepsilon \ (不一定是一步推导)$ 则有 $Follow(B) \subset Follow(A)$, 同时 $Follow(C) \subset Follow(A)$也当然满足


个人理解感觉就是:
- 直观上 $First(A)$ 中的一个元素不能对应两个不同的产生式
- 如果 $First(A)$ 中含有 $\varepsilon$, 则必须 $First(A) \cap Follow(A) = \phi$
- 2 的理解有些不对, 还是看图片的算法吧
自底向上分析
短语, 直接短语, 句柄: B 站例题
LR 分析
LL 分析需要消除左递归, LR 分析不需要消除左递归 LR(K)的含义: L: 从左到右扫描字符, R: 推导过程使用最右推导, K: 向前看 K 个字符
分析模型


LR(0)
正常构造即可
SLR(1)
DFA 与 LR(0) 相同, 分析表中规约项目的位置要根据 FOLLOW 集合写
LR(1)
LR(1) 文法的 DFA 构造: 编译原理—混子速成期末保过, 精准空降到 1:09:19
提示:
- 别忘了每个项目都要求闭包
,后面的多个字符是并列关系, 比如: $ A \rightarrow \cdot B,\ c/d $, 求 $B$ 的lookhead字符的时候是求 $First(c) \cup First(d) = { c, d }$
分析表中的规约项目的位置根据 lookhead字符 写
LALR(1)
把 LR(1) 中的同心集合并, 合并后只可能会产生规约-规约冲突
同心集:
,前面的分析相同, 只有lookhead 字符不同的式子
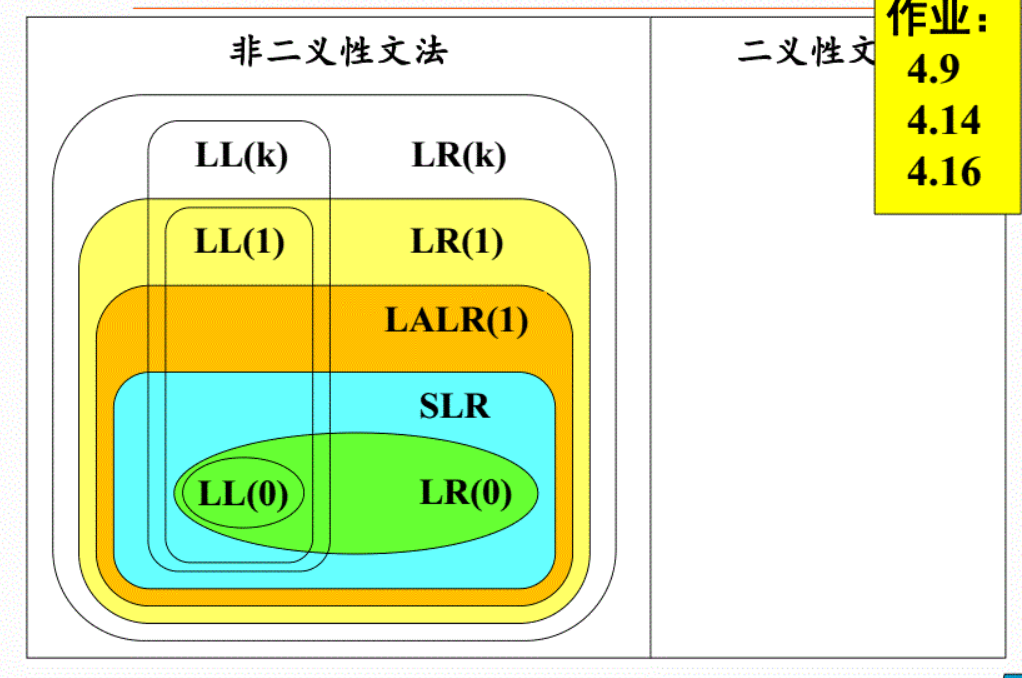
判断是否是上述几种文法的方式:
- LR(0)文法的
DFA中不存在移进-规约冲突和规约-规约冲突 (下面简称冲突), 则为 LR(0)文法; - LR(0)的
DFA中存在冲突, 但是可以通过 Follow 集合解决冲突, 则为 SLR(1)文法; - LR(1)的
DFA不存在冲突, 或存在冲突但是可以通过展望字符解决冲突, 则为 LR(1)文法; - LR(1)的
DFA合并同心集后没有产生冲突, 则为 LALR(1)文法.
语法制导翻译
很抽象的一章, 网上也找不到什么资料, 先贴个链接, 剩下的等期末复习再补全
北邮 编译原理(下)_北邮编译原理与技术期中-CSDN 博客
语义分析
C 语言对于 struct 和 union 使用名字等价, 其他类型使用结构等价
运行环境
绘制控制栈状态:
- 控制链: 由当前函数指向调用当前函数的函数;
- 访问链: 由当前函数指向代码中当前函数的上一级函数.
参数传递机制:
- 传值调用: 普通传值, 不改变原参数值;
- 引用调用: 传递值, 改变原参数值, 直接使用取地址计算;
- 复制恢复: 将参数复制一份, 会改变参数值, 与引用调用的区别如下:

- 传名调用: 只是简单的文本替换, 例子如下:

display 表:
d[i]: 指向嵌套深度为 i 的最新活动的活动记录

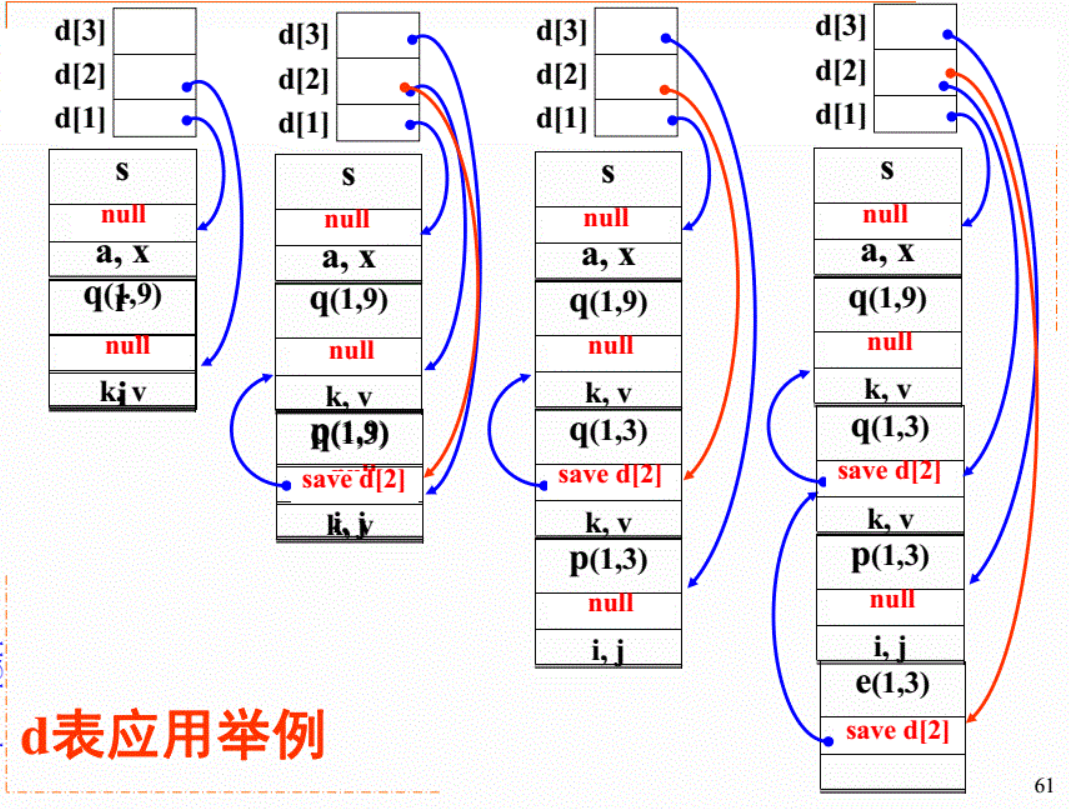
左边第二张图应该只是中间动画, 不用管
中间代码生成
【编译原理笔记 11】中间代码生成:类型表达式,声明语句的翻译_编译原理表达式翻译-CSDN 博客
目标代码生成
指令开销:和寄存器相关操作均为 0,和立即数或内 存操作为 1,移动/加法等操作为 1
代码优化
【编译原理笔记 19】代码优化: 支配结点和回边,自然循环及其识别,删除全局公共子表达式和复制语句,代码移动,作用于归纳变量的强度削弱,归纳变量的删除_编译原理 回边-CSDN 博客
基本块优化步骤:
- 常数合并及常数传播: 将
x:=2+3合并为x:=5; - 删除公共表达式: 将相同的表达式用相同的变量代替, 比如
a:=b+c, d:=b+c替换为a:=b+c, d:=a; - 复制传播: 在复制语句
f:=g后出现的f尽量用g代替; - 削弱计算强度: 删除
x:=x*1这种没有意义的计算, 将x:=y**2这种复杂的乘方计算简化成x:=y*y这种简单的乘法计算; - 改变计算次序
其中每一步都夹杂着删除死代码
循环的优化:
- 循环展开: 少量的循环展开后可能计算量会更小;
- 代码外提/频度削弱: 将循环内计算的代码提到循环外, 避免每次都计算一遍;
- 削弱计算强度: 比如用加法代替乘法, 比如在循环中需要每次获取数组元素的地址
t=i*4, 那么就可以在循环外设置变量t=0, 循环内的计算则为t=t+4; - 删除归纳变量: 依旧是上述例子, 每次循环会有一个变量
i, 称之为基本归纳变量,t则称为与i同族的归纳变量. 假定循环条件为i<10, 可以删除i, 同时将条件修改为t<40
总而言之, 就是尽量避免重复计算用更少的计算, 更少的语句达到同样的效果
