优化
慢查询
开启并查看慢日志
slow_query_log=1
# 多长时间的日志会被视为慢查询被记录
long_query_time=2
分析慢查询语句: explain/desc 查询语句

possible_keys: 可能用到的索引key: 实际用到的索引key_len: 实际用到的索引的大小extra: 额外的建议using where;using index: 查找使用了索引, 需要的数据都在索引中找到, 不需要回表using index condition: 查找使用了索引, 但是需要回表查询数据, 使用了索引下推(在引擎层使用索引中的字段进行过滤, 减少返回给 server 层的数据, 从而减少回表次数)using filesort: order by 中使用的字段没有被索引覆盖
type: sql 连接类型, 性能好到差为: NULL > system (mysql 系统的表) > const (主键查询) > eq_ref (主键索引或者唯一索引, 返回一条数据) > ref (索引查询, 可能多条数据) > range (索引, 范围查询) > index (索引树查询) > all (全表查询)
索引
B+树和 B 树区别:
- B+树在非叶子节点上只存储指针不存储数据, 查询代价更低
- 叶子节点之间有双向指针, 便于区间查询
使用覆盖索引处理超大分页问题:
select * from user limit 1000000, 10;
上述语句会查询 10000010 条数据, 然后舍弃前 1000000 条数据, 可以用覆盖索引+子表查询进行优化
select * from user u,
(select id from user order by id limit 1000000, 10) t
where u.id = t.id;
子查询中使用了覆盖索引进行查询和排序
最左前缀法则: 如果索引了多列, 需要遵守最左前缀法则. 查询从索引的最左前列开始, 并且不跳过索引中的列.
索引失效:
- 违反最左前缀法则, 则索引失效; 或者符合法则但是跳过某一列, 则只有最左列索引起效. 复合索引(a, b, c),
a = 1 and c = 3, 只有 a 使用了索引 - 范围查询右边的列不能使用索引.
a = 1 and b > 2 and c = 3, a, b, c 都有索引, 则只有 a 和 b 索引生效 - 在索引列上进行运算操作.
substring(a, 1, 1) = 1, a 的索引失效 - 字符串不加单引号(也就是类型转换)
- 以
%开头的like模糊查询, 如a like '%aa', 索引会失效 (但如果只是尾部模糊匹配, 如a like 'aa%'则不会失效)
优化方法
-
表的设计 (阿里开发手册)
- 合适数值类型: tinyint, int, bigint
- 合适字符串类型: char 定长效率高, varchar 变长效率低
-
索引创建原则
-
SQL 语句优化
select指明字段明, 避免select *;- SQL 避免索引失效
- 使用
union all代替union(会多一次过滤, 效率低) - 避免在
where中对字段进行表达式操作 join优化尽量用inner join不用left join,right join, 必须要用则要以小表为驱动.inner join会优化, 优先将小表放到外边, 大表放到里面,left/right join则不会
-
主从复制、读写分离
-
分库分表
事务
- 原子性(Atomicity): 事务是不可分割的最小单元, 要么全部成功, 要么全部失败;
- 一致性(Consistency): 事务完成时, 必须使所有的数据都保持一致状态;
- 隔离性(Isolation): 数据库系统提供的隔离机制, 保证事务在不受外部并发操作影响的独立环境下运行;
- 持久性(Durability):事务一旦提交或回滚, 它对数据库中的数据的改变就是永久性的;
| 读未提交 | 读已提交 | 可重复读 | 可串行化 | |
|---|---|---|---|---|
| 脏读 | √ | √ | √ | |
| 不可重复读 | √ | √ | ||
| 幻读 | √ |
MySQL 操作并不会直接操作磁盘,会先将磁盘中的数据拿到内存的 Buffer Pool 中,操作完成后一定频率再持久化到磁盘上。
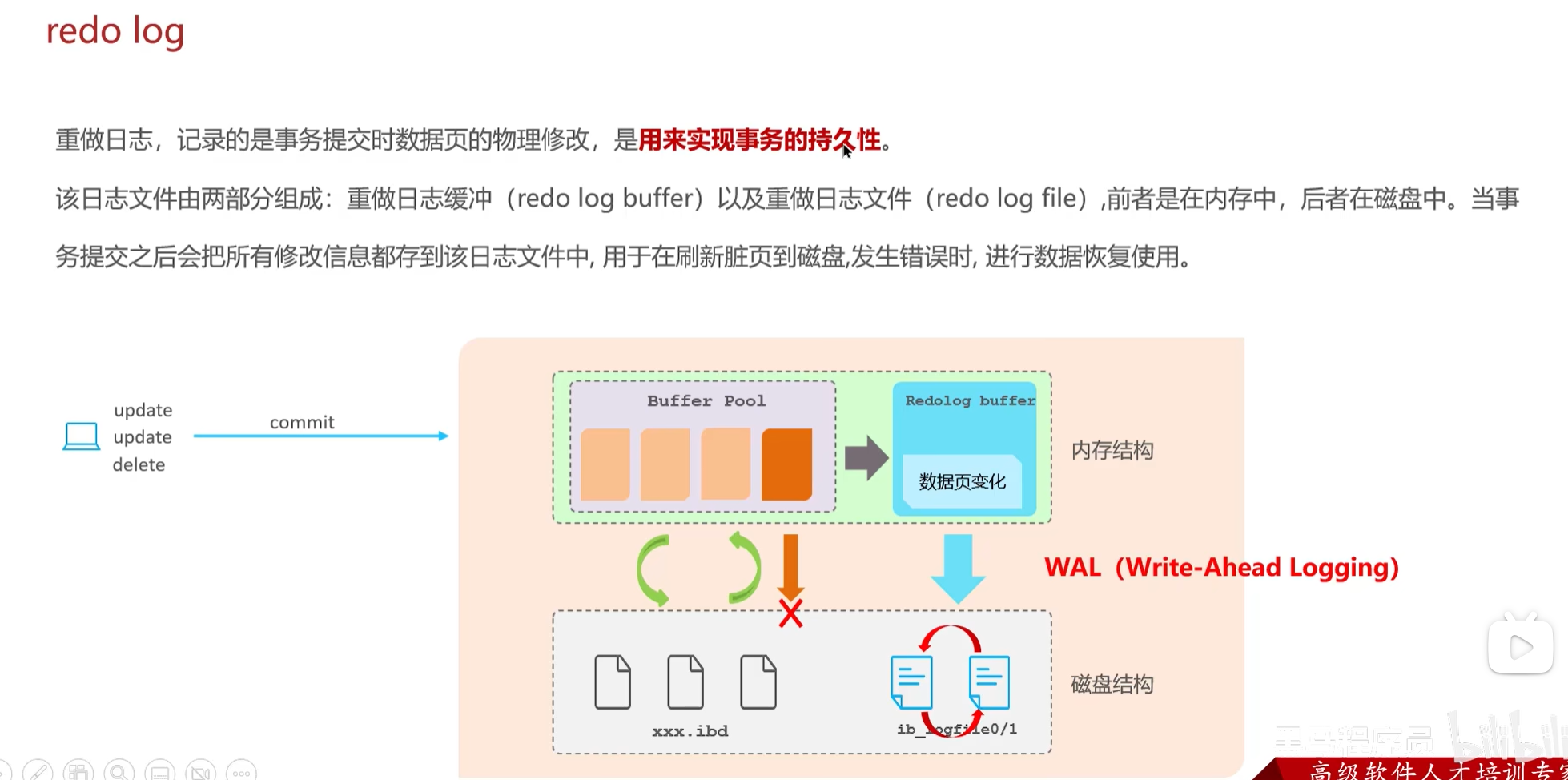
undo log 记录日志与实际操作相反,事务回滚时实现事务的一致性和原子性
MVCC
MVCC: Multi-Version Concurrency Control, 多版本并发控制. 维护一个数据的多个版本, 使得读写操作没有冲突.
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务 ID, 记录擦汗如这条记录或最后一次修改该记录的事务 ID |
| DB_ROLL_PTR | 回滚指针, 指向这条记录的上一个版本, 用于配合 undo log, 指向上一个版本 |
| DB_ROW_ID | 隐藏主键, 如果表结构没有指定主键, 将会生成该隐藏字段 (没有指定主键时使用) |
- undo log 版本链: 不同事务或相同事务对同一条记录修改, 会导致该记录的 undo log 生成一条记录版本链表, 头是最新的旧记录, 尾是最早的旧记录
- ReadView: 快照读执行时 MVCC 提取数据的依据, 记录并维护系统当前活跃的事务(未提交)id
ReadView 核心字段
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃事务 id 集合 |
| min_trx_id | 最小活跃事务 id |
| max_trx_id | 预分配事务 id, 当前最大事务 id+1 |
| creator_trx_id | ReadView 创建者的事务 id |
版本链数据访问规则:
- trx_id == creator_trx_id 可以访问, 数据是当前事务更改的
- trx_id < min_trx_id 可以访问, 数据已经提交
- trx_id > max_trx_id 不可以访问, 事务在 ReadView 创建后开启
- min_trx_id <= trx_id <= max_trx_id trx_id 不在 m_ids 中则可以访问, 说明已提交
RC: 事务中每一次快照读都会生成 ReadView
RR: 事务中只有第一次快照读生成 ReadView
主从同步
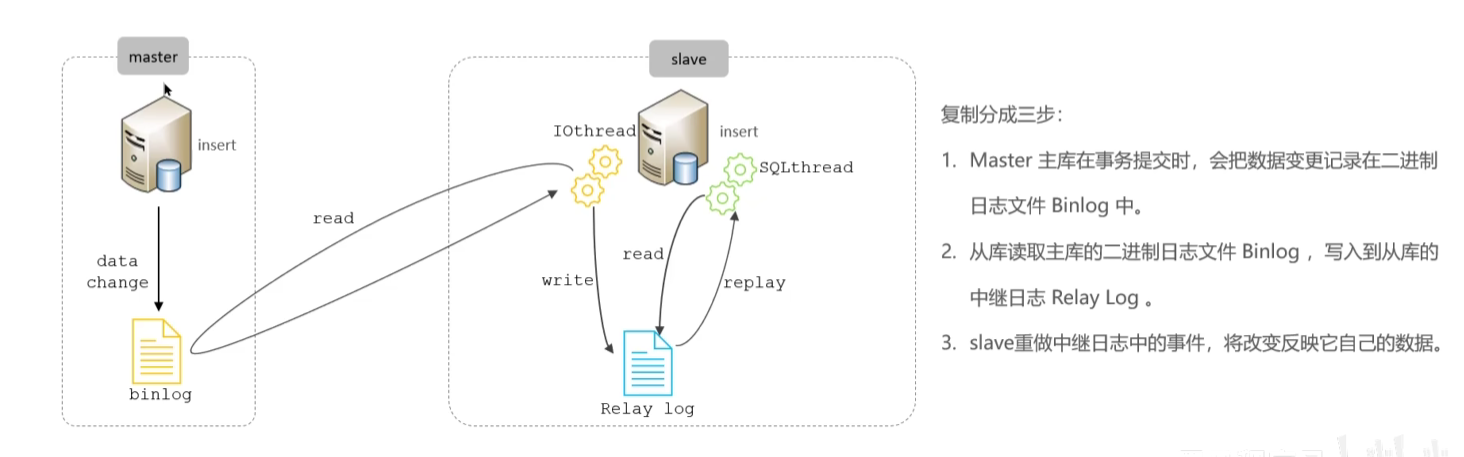
主从复制类型:
- 异步:默认方式,发送给 slave 后不管结果
- 同步:所有 slave 完成事务后 master 再提交该事务
- 半同步:有一个 slave 写入到 relay log 后返回 commit,master 完成该事务,slave 后续步骤仍为异步
分库分表
垂直拆分
-
垂直分库: 以表为依据, 根据业务将不同表拆分到不同库中.
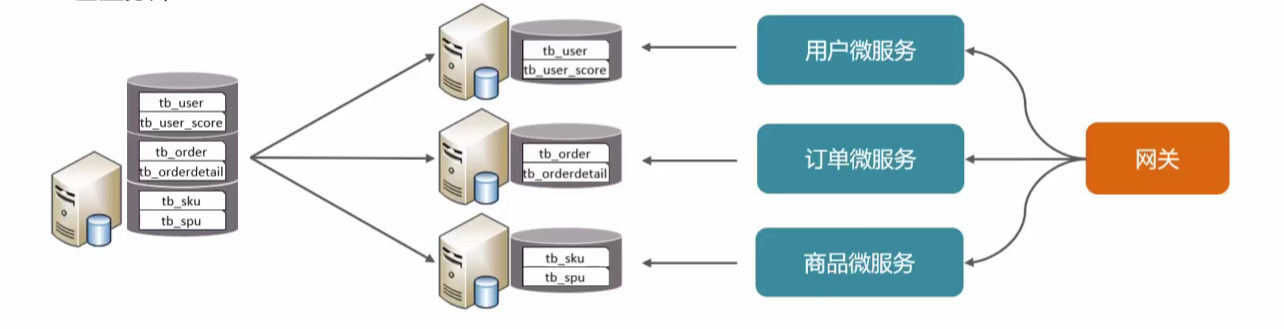
- 按业务对数据分级管理, 维护, 监控, 扩展
- 高并发下, 提高磁盘 IO 和数据量连接数
-
垂直分表: 以字段为依据, 根据字段属性将不同字段拆分到不同表中
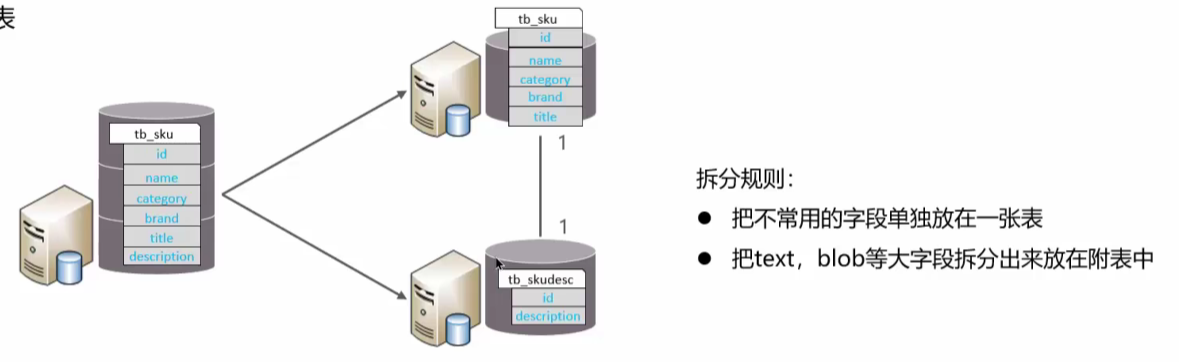
- 冷热数据分离
- 减少 IO 过度争抢, 两表互不影响
水平拆分
-
水平分库: 将一个库的数据拆分到多个库中
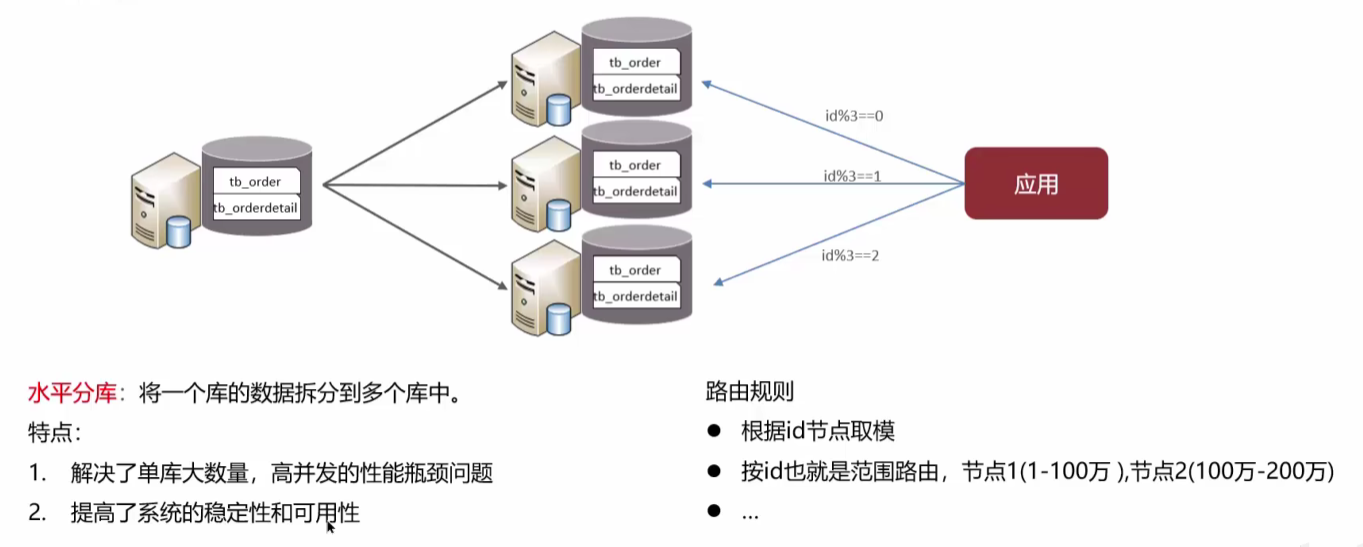
-
水平分表: 将一个表的数据拆分到多个表中
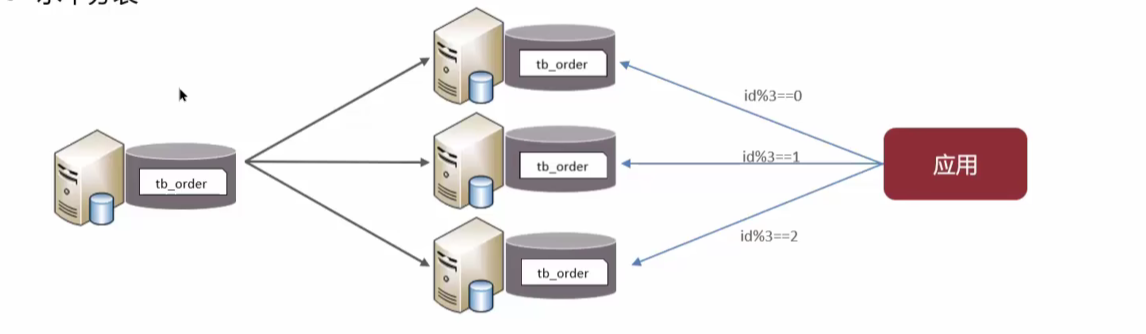
- 优化但仪表数据量过大而产生的性能问题
- 避免 IO 争抢并减少锁表的几率
