GC(Garbage Collection) 垃圾回收,是编程语言中自动管理内存的一种机制,它能够自动识别并释放不再使用的内存空间,从而避免内存泄漏。GC 是编程语言中非常重要的一部分,对于提高程序的性能和稳定性具有重要意义。
Java 中的 GC 演变史
Java 中垃圾回收器经历了多个版本的迭代和改进,从一开的串行回收器到并行回收器,再到 G1(Garbage First)回收器,再到 ZGC(Z Garbage Collector)回收器,每一代的垃圾回收器都朝着更低的停顿时间(STW, Stop The World)和支持更大的堆这两个目标前进,接下来将简要介绍一下 CMS、G1 以及 ZGC 这三种垃圾回收器。
CMS 回收器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,基于并发标记清理实现,在标记清理过程中不会导致用户线程无法定位引用对象。仅作用于老年代收集。它的步骤如下:
- 初始标记(CMS initial mark):独占 CPU,STW,仅标记 GCroots 能直接关联的对象,速度比较快;
- 并发标记(CMS concurrent mark):可以和用户线程并发执行,通过 GCRoots Tracing 标记所有可达对象;
- 重新标记(CMS remark):独占 CPU,STW,对并发标记阶段用户线程运行产生的垃圾对象进行标记修正,以及更新逃逸对象;
- 并发清理(CMS concurrent sweep):可以和用户线程并发执行,清理在重复标记中被标记为可回收的对象。
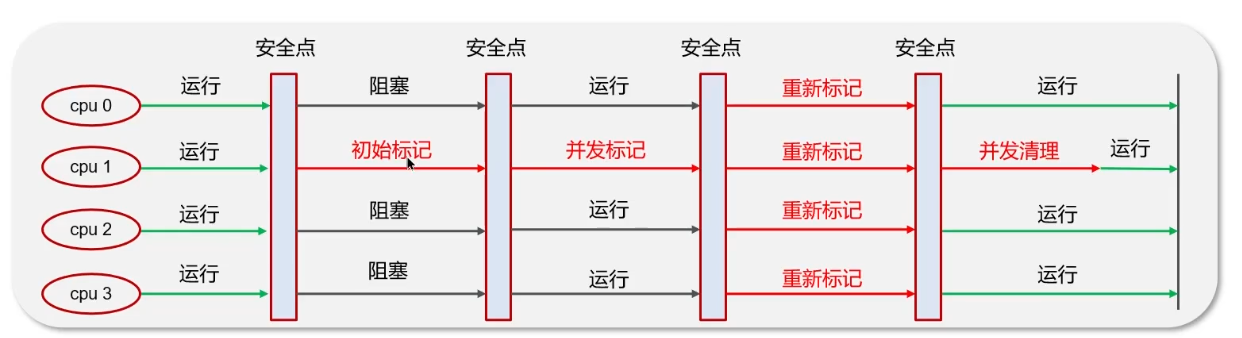
可以看到 CMS 在重新标记时有一次 STW,以及并发标记和并发清理时需要占用一部分用户线程的资源,并且在清理时如果用户线程分配了大于剩下内存的对象,则会引发 Concurrent Mode Fail 的问题,此时会立刻暂停用户进程并且开启 Serial 收集器进行垃圾回收清理的操作。当垃圾回收完成之后,会开启用户用户线程并且恢复 CMS 收集器的工作。
并且如前面提到的,CMS 是主要是基于标记清理实现,在上述流程中只是对对象进行了标记和清理,并没有涉及到对象的移动,这就导致了内存碎片化,如果此时新生代出现大对象要进来,很容易造成频繁 Full GC,严重影响性能。官方对于此问题的解决方法是:在一定次数的 Full GC 后(默认 0 次,也就是每次 GC 都进行),进行一次标记整理,此阶段也是需要 STW,这对性能也会有一定影响。
G1 回收器
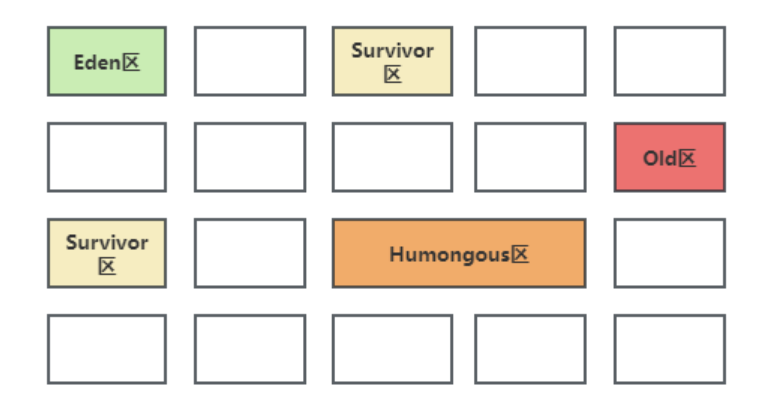
从上面的结构图中可以看到 G1 收集器的内存结构完全区别去 CMS,弱化了 CMS 原有的分代模型,将堆内存划分成一个个 Region,这样有利于更灵活地管理堆。G1 的混合回收过程可以分为标记阶段、清理阶段和复制阶段。
标记阶段
- 初始标记阶段:初始标记阶段是指从 GC Roots 出发标记全部直接子节点的过程,STW,但阶段耗时比较短。
- 并发标记阶段:并发标记阶段是指从 GC Roots 开始对堆中对象进行可达性分析,找出存活对象。该阶段应用线程和 GC 线程可以可以同时活动,所以虽然并发标记耗时相对长很多,但因为不是 STW,可以不用过多关注。
- 再标记阶段:重新标记那些在并发标记阶段发生变化的对象。该阶段是 STW 的。
清理阶段
清理阶段清点出有存活对象的分区和没有存活对象的分区,该阶段不会清理垃圾对象,也不会执行存活对象的复制。该阶段是 STW 的。
复制阶段
复制算法中的转移阶段需要分配新内存和复制对象的成员变量。转移阶段是 STW 的,其中内存分配通常耗时非常短,但对象成员变量的复制耗时有可能较长,这是因为复制耗时与存活对象数量与对象复杂度成正比。对象越复杂,复制耗时越长。1
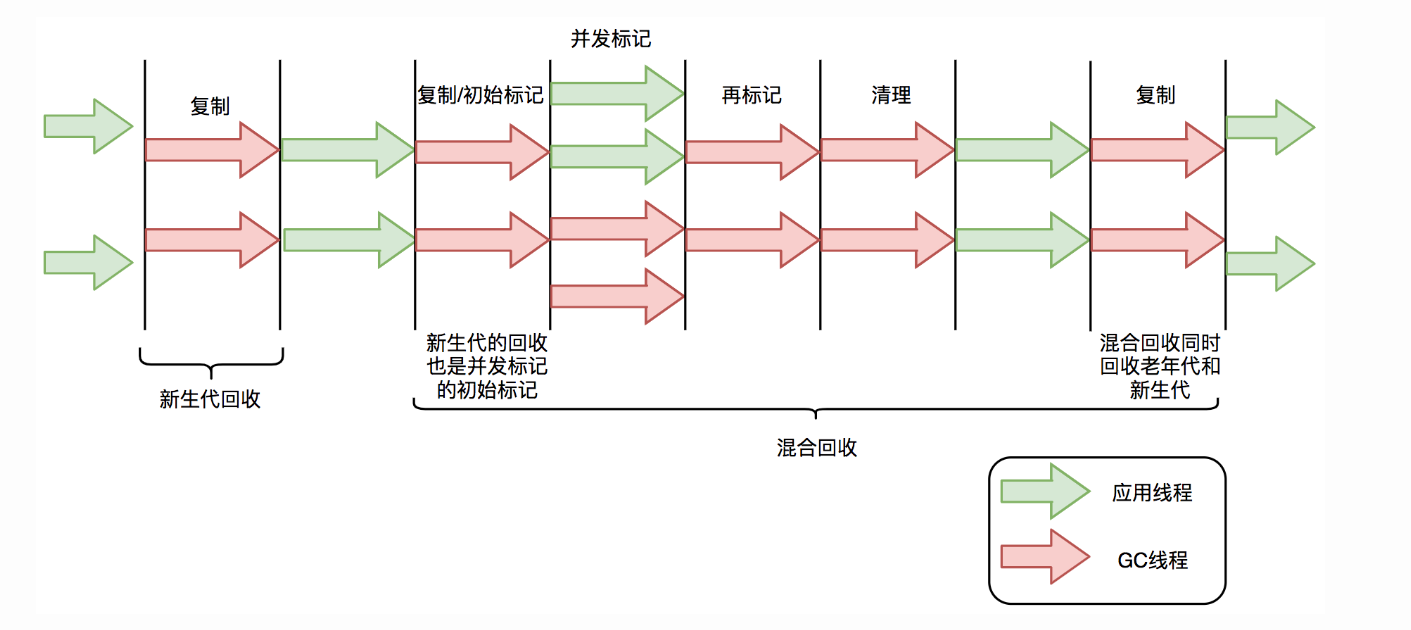
上述三个阶段中,标记阶段因为对象较少,清理阶段因为分区较少,他们的 STW 时间也比较少,但是复制阶段因为对象多且复杂,所以 STW 时间较长。此时可以想到,如果让复制阶段也和用户线程并发处理,这样则可以大大提升性能,由此引出了 ZGC。
ZGC 回收器
ZGC 和 G1 一样也使用了标记复制算法,不过 ZGC 对该算法做了重大改进:ZGC 在标记、转移和重定位阶段几乎都是并发的。
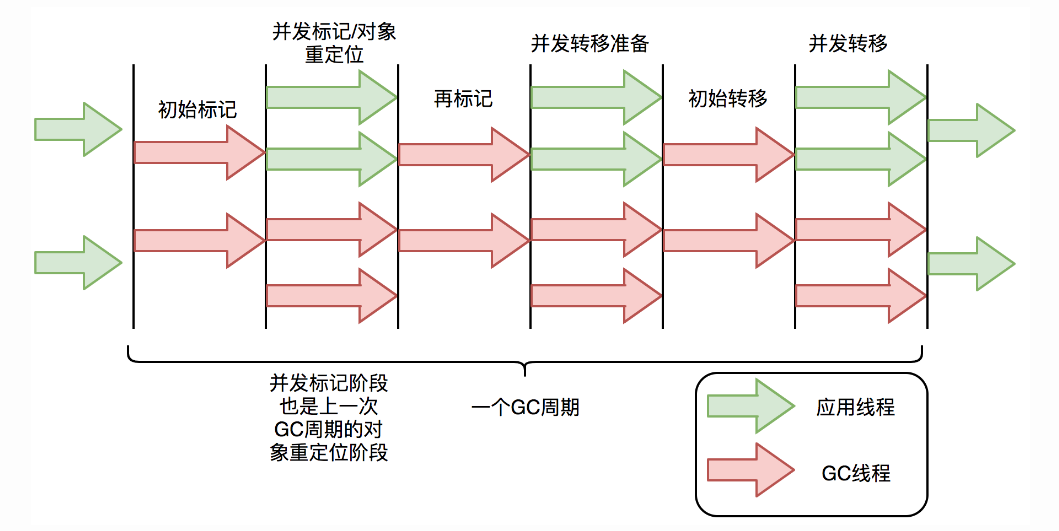
ZGC 只有三个 STW 阶段:初始标记,再标记,初始转移。其中,初始标记和初始转移分别都只需要扫描所有 GC Roots,一般情况耗时非常短;再标记阶段 STW 时间也很短,最多 1ms,超过 1ms 则再次进入并发标记阶段。1
在 G1 中,复制阶段无法并发的原因是无法确定对象的地址,如果此时对象移动,则用户线程会访问到错误地址,从而导致错误。在 ZGC 中,通过着色指针和读屏障两个关键技术解决了此问题。大概原理是:当用户线程访问对象将触发“读屏障”,如果发现对象被移动了,那么“读屏障”会把读出来的指针更新到对象的新地址上,这样用户线程始终访问的都是对象的新地址
着色指针:一种将信息存储在指针中的技术。
读屏障:JVM 向应用代码插入一小段代码的技术。当应用线程从堆中读取对象引用时,就会执行这段代码。
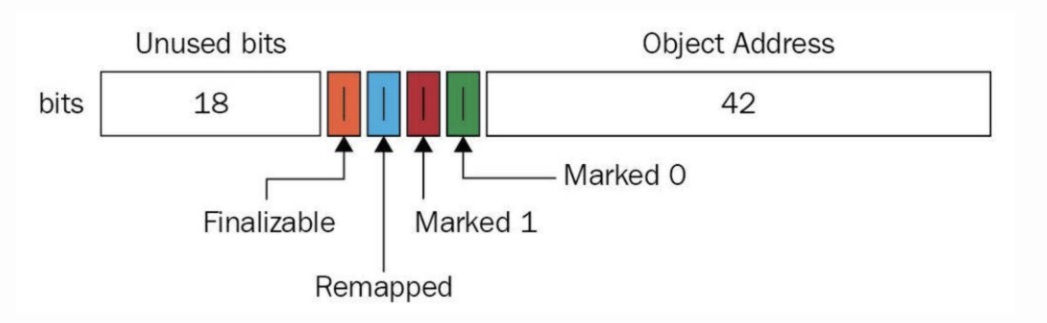
着色指针的结构如下:
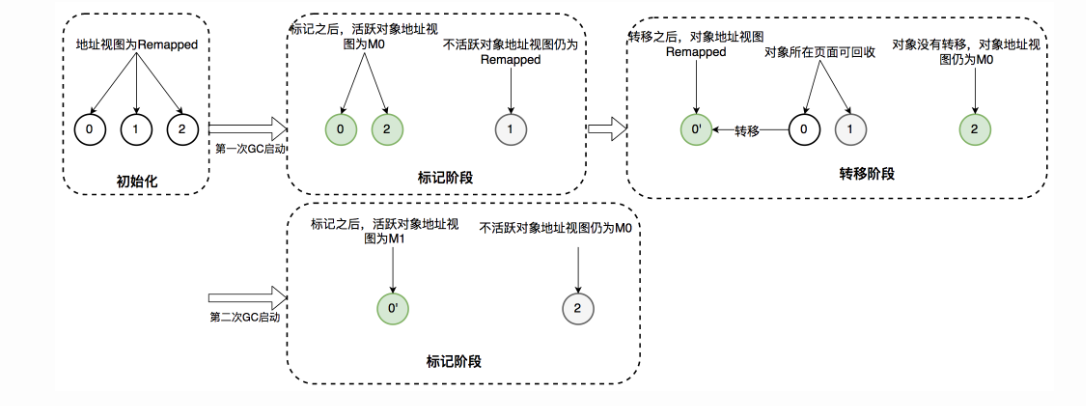
ZGC 中地址视图的切换过程:
- 初始化:ZGC 初始化之后,整个内存空间的地址视图被设置为 Remapped。程序正常运行,在内存中分配对象,满足一定条件后垃圾回收启动,此时进入标记阶段。
- 并发标记阶段:第一次进入标记阶段时视图为 M0,如果对象被 GC 标记线程或者应用线程访问过,那么就将对象的地址视图从 Remapped 调整为 M0。所以,在标记阶段结束之后,对象的地址要么是 M0 视图,要么是 Remapped。如果对象的地址是 M0 视图,那么说明对象是活跃的;如果对象的地址是 Remapped 视图,说明对象是不活跃的。
- 并发转移阶段:标记结束后就进入转移阶段,此时地址视图再次被设置为 Remapped。如果对象被 GC 转移线程或者应用线程访问过,那么就将对象的地址视图从 M0 调整为 Remapped。
标记阶段存在两个地址视图 M0 和 M1,这是为了区别前一次标记和当前标记。当第二次进入并发标记阶段后,地址视图调整为 M1,而非 M0。
可以看到,着色指针和读屏障技术不仅应用在并发转移阶段,还应用在并发标记阶段设置对象状态。相比于传统的垃圾回收器需要进行一次内存访问,并将对象存活信息放在对象头中;在 ZGC 中,只需要设置指针地址的第 42~45 位即可,并且因为是寄存器访问,所以速度比访问内存更快。
Go 语言中的垃圾回收
与 Java 不同的是,Go 中的 GC 是不分代的 GC,没有新生代和老年代的划分。这是因为 Go 会在编译阶段进行逃逸分析,将生命周期长的对象分配到堆上,生命周期短的对象分配到栈上,GC 只需要关注堆上的对象即可。
一个逃逸分析的例子
package main
import "fmt"
type Person struct {
Name string
}
func NewPerson(name string) *Person {
p1 := &Person{Name: name}
p2 := &Person{}
p2.Name = p1.Name
return p2
}
func main() {
p := NewPerson("demo")
fmt.Println(p)
}
执行结果
go build -gcflags=-m main.go
# command-line-arguments
.\main.go:9:6: can inline NewPerson
.\main.go:17:16: inlining call to NewPerson
.\main.go:18:13: inlining call to fmt.Println
.\main.go:9:16: leaking param: name
.\main.go:10:8: &Person{...} does not escape
.\main.go:11:8: &Person{} escapes to heap
.\main.go:17:16: &Person{...} does not escape
.\main.go:17:16: &Person{} escapes to heap
.\main.go:18:13: ... argument does not escape
可以看到第 10 行的&Person{}(也就是p1)没有逃逸,是在栈上分配,而第 11 行的&Person{}(也就是p2)因为函数返回了这个指针,所以逃逸到了堆上。
内存分配
Go 的内存分配是基于 TCMalloc 改造的一种内存分配方式,这种分配方式高效,减少并发粒度,并且没有内存碎片。2
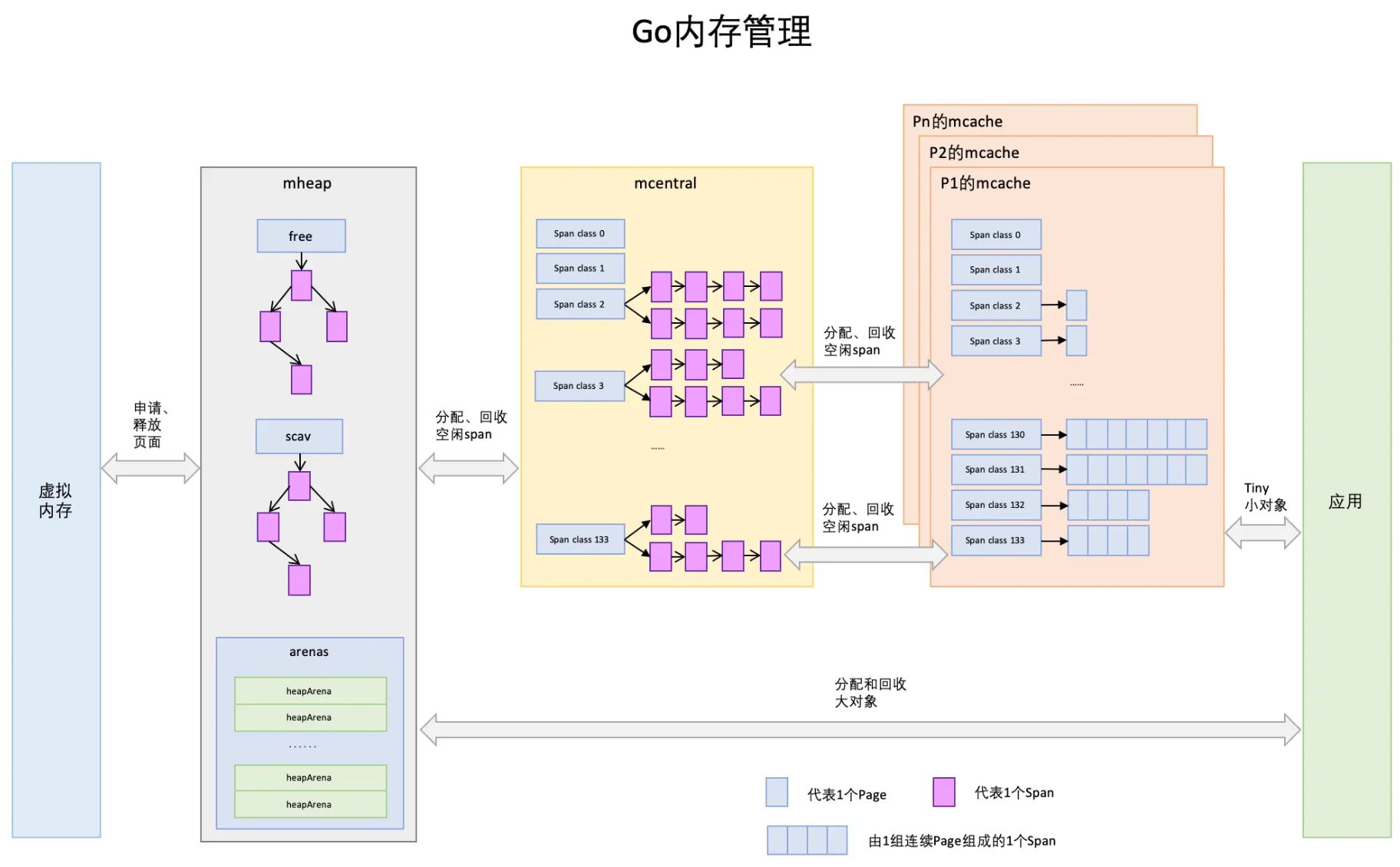
这里我们不再表述 TCMalloc 的分配方式,直接进入到 Go 的内存分配模型。Go 的内存管理如上图,实际上已经非常清楚了,下面是几个要点:
- 一个 Span 由一组连续的 Page 组成,Span 是内存管理的基本单位;
- mcache 保存的是各种大小的 Span,并按 Span class 分类,小对象直接从 mcache 分配内存,它起到了缓存的作用,并且可以无锁访问,在 Go 中每个 P 都有一个 mcache;
- mcentral 是所有线程共享的缓存,需要加锁访问;
- mheap 是堆内存的抽象,把从 OS 申请出的内存页组织成 Span,并保存起来。
除了上面的内存分配模型,还有一个大小转换在内存分配中也起到了很大的作用:
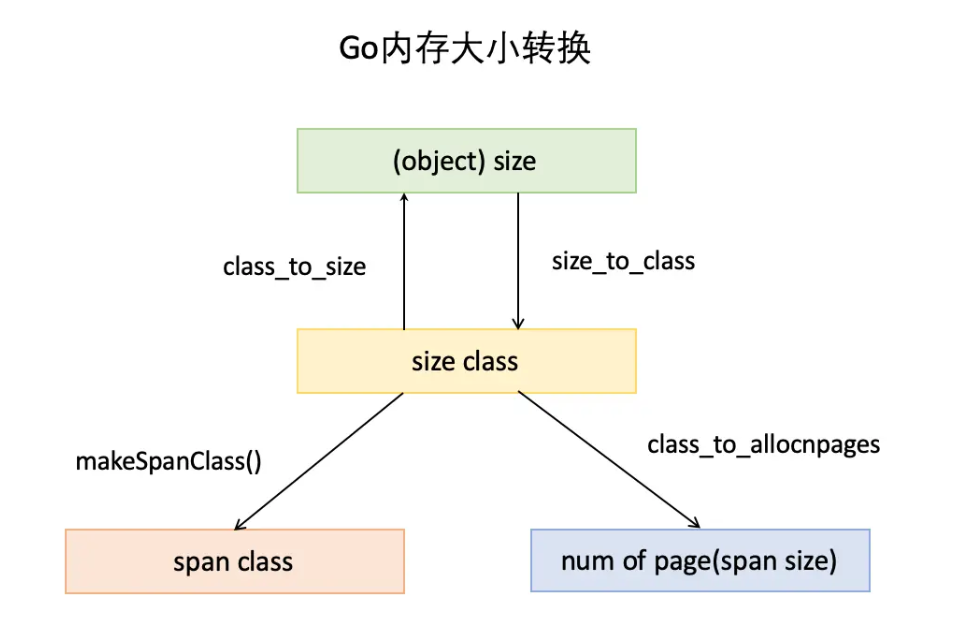
- object size:代码里简称 size,指申请内存的对象大小;
- size class:代码里简称 class,它是 size 的级别,相当于把 size 归类到一定大小的区间段,比如 size[1,8]属于 size class 1,size(8,16]属于 size class 2;
- span class:指 span 的级别,但 span class 的大小与 span 的大小并没有正比关系。span class 主要用来和 size class 做对应,1 个 size class 对应 2 个 span class,2 个 span class 的 span 大小相同,只是功能不同,1 个用来存放包含指针的对象,一个用来存放不包含指针的对象,不包含指针对象的 Span 就无需 GC 扫描了;
- num of page:代码里简称 npage,代表 Page 的数量,其实就是 Span 包含的页数,用来分配内存。
Go 中根据对象大小仅分为小对象和大对象,小对象从 mcache 中分配,大对象从 mheap 中分配内存。
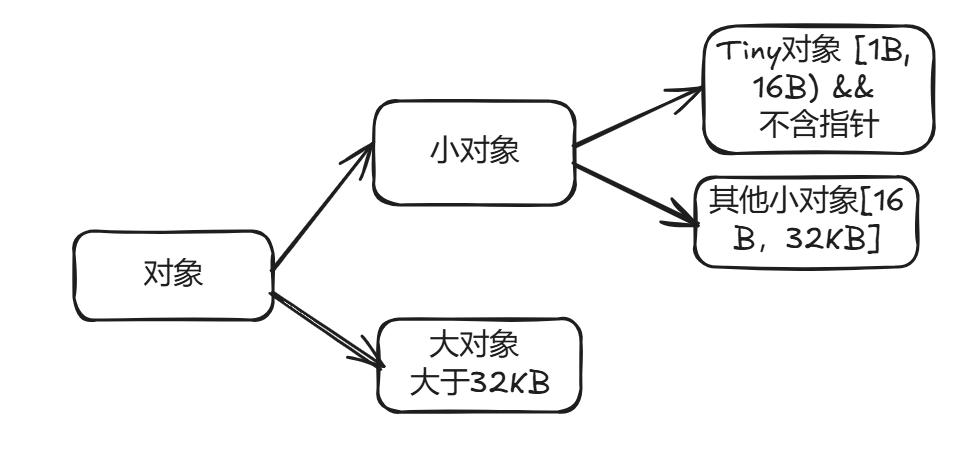
当分配一个对象时,需要为该对象寻找 Span,此流程如下:
- 计算对象所需内存大小 size;
- 根据 size 到 size class 映射,计算出所需的 size class;
- 根据 size class 和对象是否包含指针计算出 span class;
- 获取该 span class 指向的 span。
如果 Span 不够,mcache 则会从 mcentral 中请求 Span。mcentral 中的每个 Span class 包含有两个链表:一个链表里面的所有 Span 都至少有 1 个空闲的对象空间,叫做 nonempty;另一个链表中的所有 Span 都不确定里面是否有空闲的对象空间,叫做 empty。每次优先从 nonempty 中寻找合适 Span,如果没找到再从 emtpy 搜索满足条件的 Span,然后把找到的 Span 交给 mcache。
上面内存模型图中的 mheap 中也有三个数据结构,这里介绍如下:
- free:保存的 Span 是空闲并且非垃圾回收的 Span,比如从操作系统中申请的内存组成的 Span;
- scav:保存的是空闲并且已经垃圾回收的 Span,比如垃圾回收后释放的 Span;
- arenas:由一组 heapArena 组成,每一个 heapArena 都包含了连续的 pagesPerArena 个 Span,这个主要是为 mheap 管理 Span 和垃圾回收服务。
垃圾回收
在看完 Go 的内存分配后,我们正式进入到 Go 的垃圾回收,Go 的 GC 大致分为标记和清扫两个阶段:
- 标记阶段:从根对象出发查找并标记堆中所有存活的对象;
- 清扫阶段:遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表。
在标记阶段 Go 使用了三色标记法来减少 STW 时间(前面 CMS 和 G1 中使用的标记算法也是此方法)。
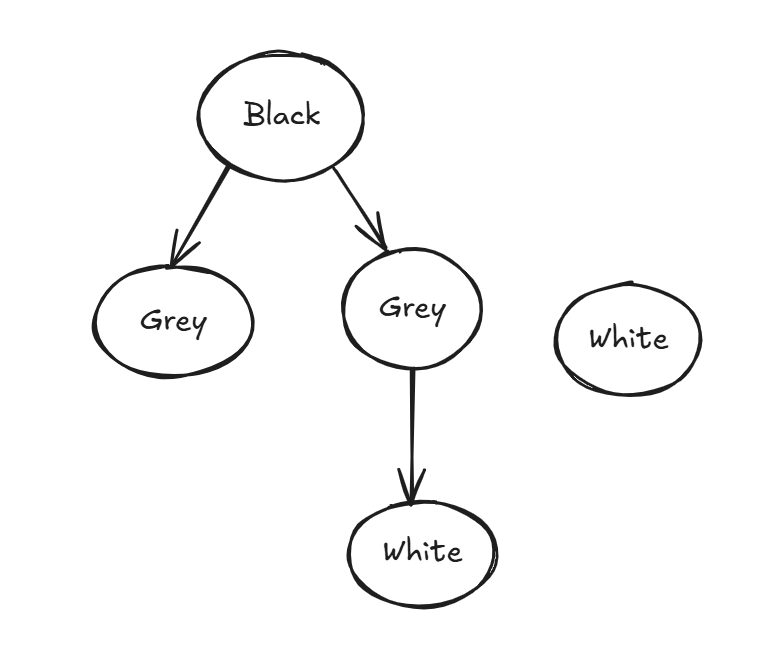
简要来讲,三色标记就把对象标记为黑、灰、白三种颜色,三种颜色含义如下:
- 黑色:已经被标记完的对象
- 灰色:正在标记的对象,子节点会有白色对象
- 白色:还没有被标记的对象
标记过程如下3:
- 首先把所有的对象都放到白色的集合中;
- 从根节点开始遍历对象,遍历到的白色对象从白色集合中放到灰色集合中;
- 遍历灰色集合中的对象,把灰色对象引用的白色集合的对象放入到灰色集合中,同时把遍历过的灰色集合中的对象放到黑色的集合中;
- 循环步骤 3,直到灰色集合中没有对象;
- 步骤 4 结束后,白色集合中的对象就是不可达对象,也就是垃圾,进行回收。
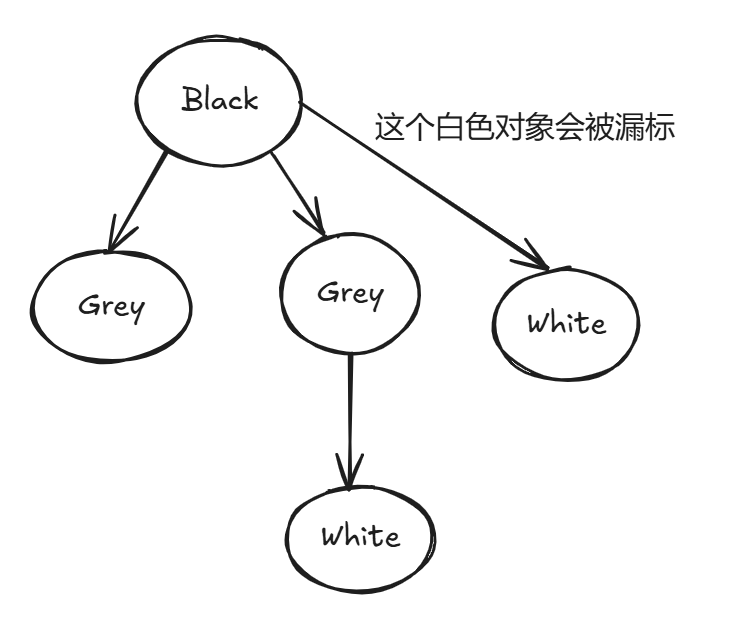
从上面可以看到如果在标记时一个用户线程恰巧让一个黑色对象引用一个白色对象,这个白色对象又没有被其他的灰色对象引用,因为黑色对象已经被标记完无法再次标记,此时这个白色对象将会被漏标。
一套解决上述漏标问题的方法被称为强弱三色不变式:
- 强三色不变式:白色对象不能被黑色对象直接引用;
- 弱三色不变式:白色对象可以被黑色对象引用,但要从某个灰对象出发仍然可达该白对象
Go 语言中为了解决上述问题,引入了插入写屏障和删除写屏障,这两个合称为混合写屏障。
插入写屏障
黑色对象试图指向白色对象时触发插入写屏障,白色对象先被置灰,然后再完成指向。
删除写屏障
白色对象被删除引用前出发删除写屏障,先被置灰,然后再被删除引用。
在实际实现中,因为栈对象涉及到频繁的轻量操作,这些操作如果都要触发屏障机制则会对性能产生极大影响,因此写屏障对栈对象不起作用,所以 Go 需要同时引入插入写屏障和删除写屏障来解决漏标问题,最终机制如下:
- GC 开始前,以栈为单位分批扫描,将栈中所有对象置黑;
- GC 期间,栈上新创建对象直接置黑;
- 堆对象正常启用插入写屏障;
- 堆对象正常启用删除写屏障
